
Nous avons expliqué précédemment comment collecter des tweets. Il peut être intéressant de « découper » ces messages en mots afin de procéder à des analyses de fréquences. Cela est utile pour analyser les discours au sein d’un corpus. Je vous propose une méthode simple à mettre en oeuvre à l’aide de Talend.
D’abord, authentifiez-vous à Twitter et effectuez votre requête comme expliqué dans le précédent tutoriel. Puis, construisez le job de formatage des données suivant à l’aide des composants tReplace, tMap, tFilterRow, tNormalize et tFileOutputExcel.
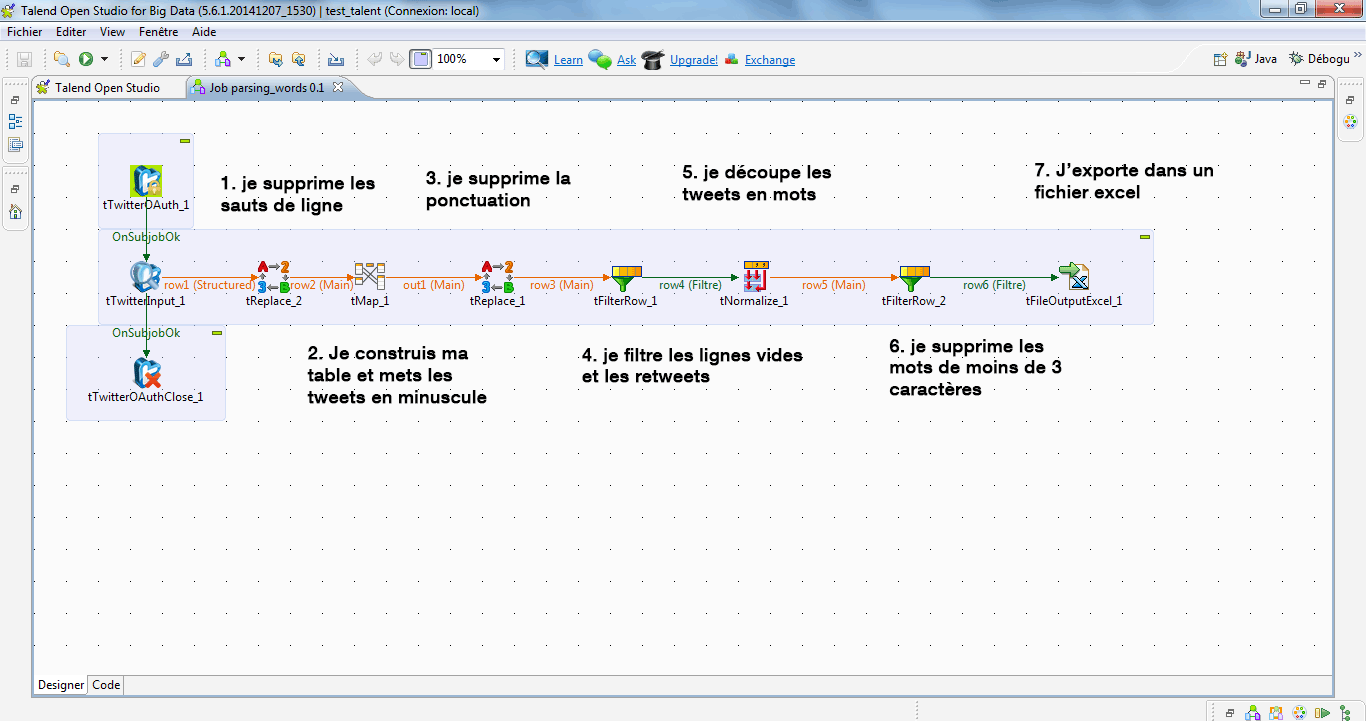
Kilkenny > Configuration de tTwitterInput
Notre requête sur tTwitterInput récupère les champs ‘text’, ‘status id’, ‘sender’s id’ et ‘is retweet’.
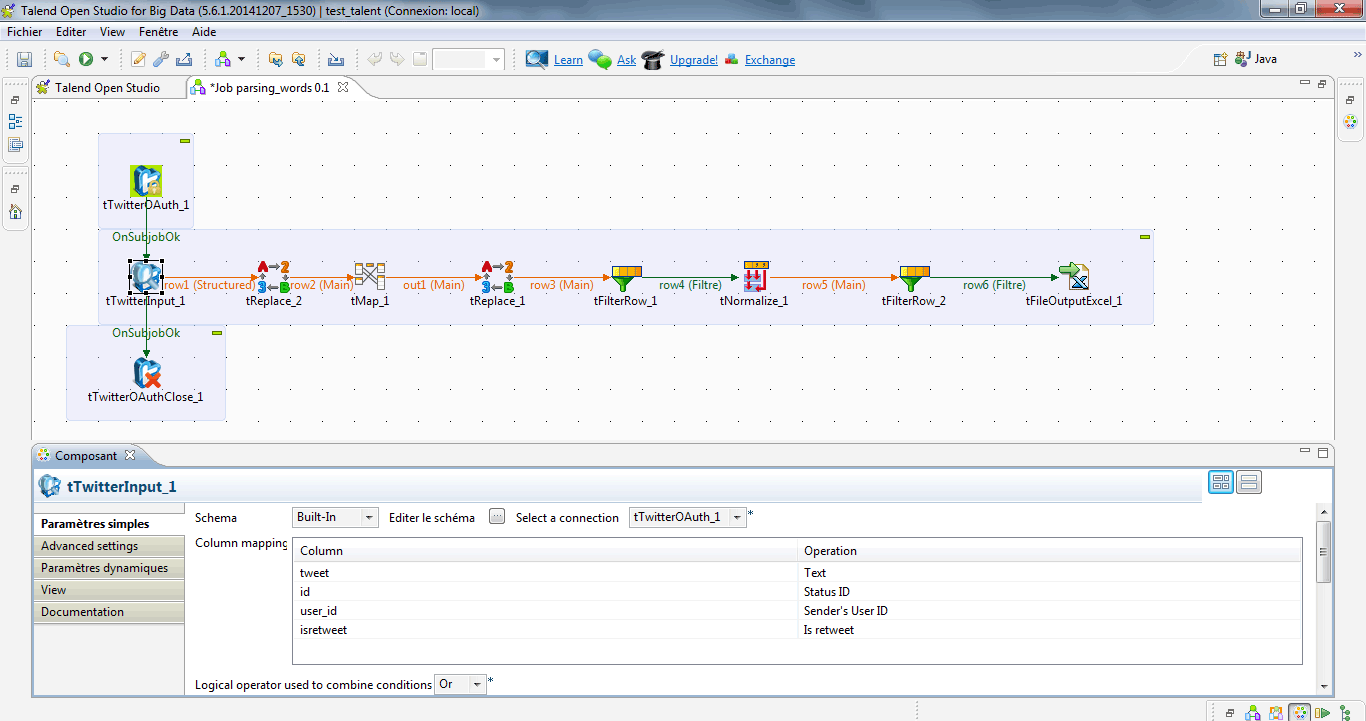
annonces libertines à bobigny > Supprimer les sauts de ligne
A l’aide du composant tReplace, je sélectionne le champ tweet et supprime tous les sauts de ligne en recherchant la séquence « \n ».
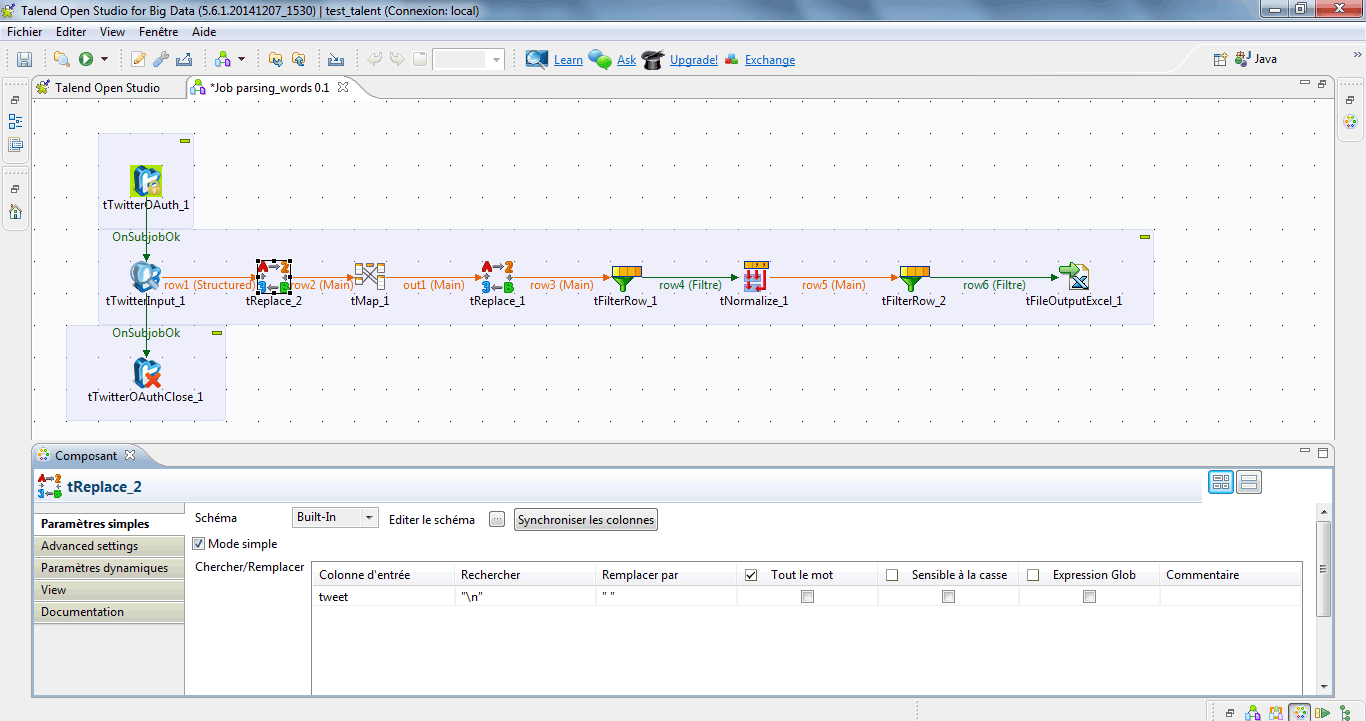
Rubtsovsk > Passer les tweets en minuscules
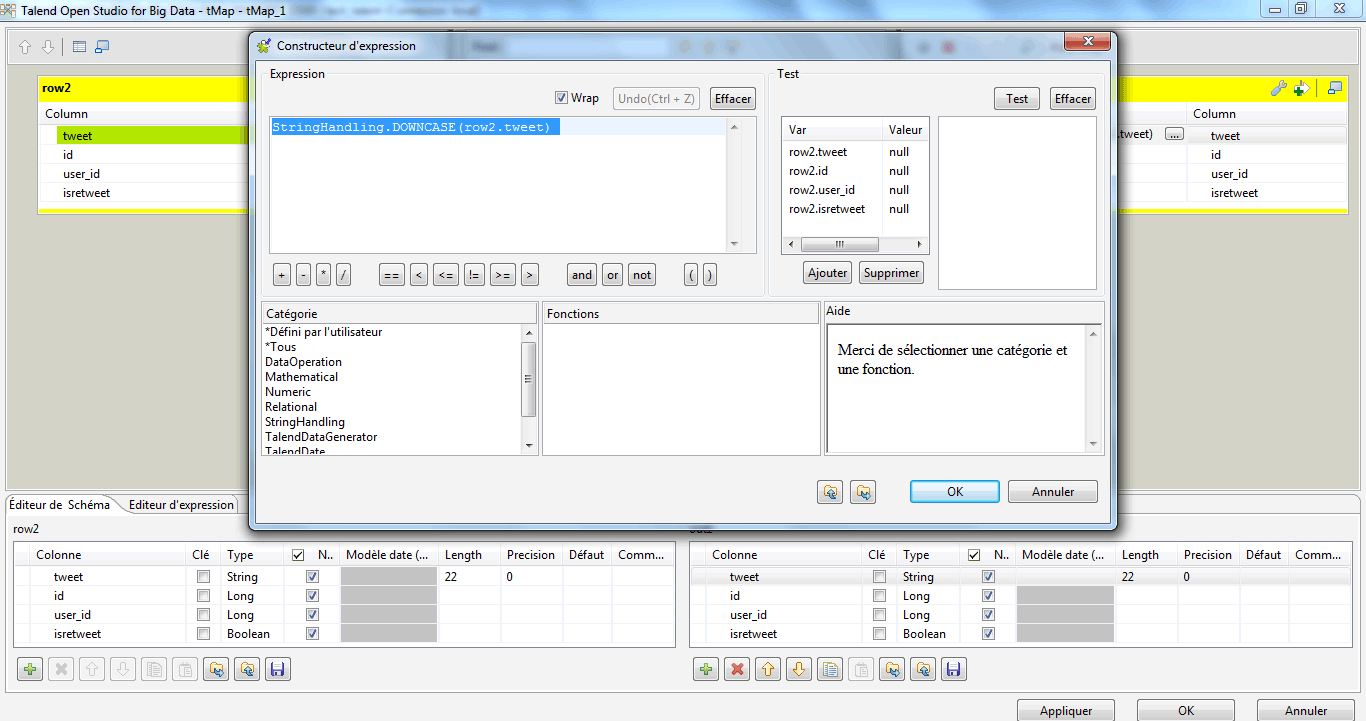
A l’aide du composant tMap, nous allons construire nos tables en prévision de son exportation sous un format de fichier excel. On procède de la manière expliquée dans le précédent tuto, mais on ajoute à cela une petite complexité. Je clique sur le champ row2.tweet pour lui appliquer un filtre.
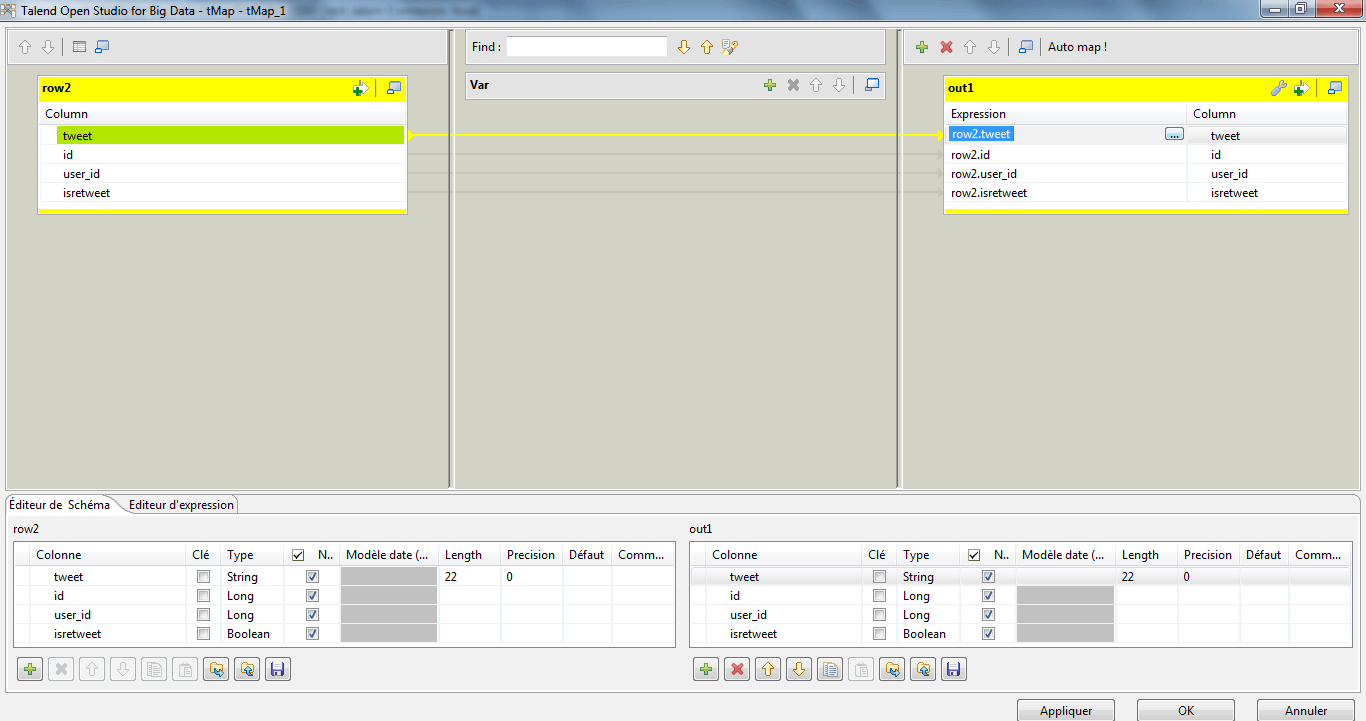
J’utilise la fonction downcase() pour passer tous les caractères du tweet en minuscule. Je tape : StringHandling.DOWNCASE(row2.tweet)
> Supprimer toute la ponctuation
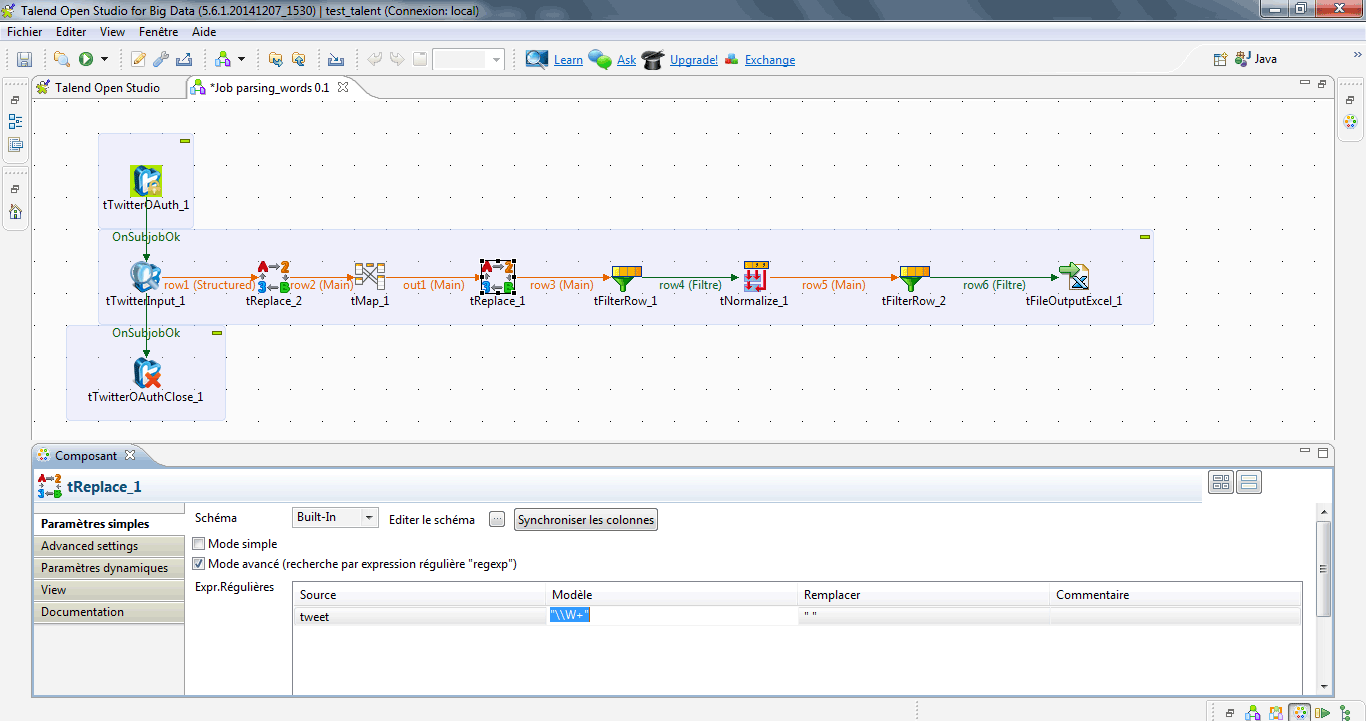
A l’aide du composant tReplace, je remplace la ponctuation par des espaces à l’aide de l’expression régulière « \\W+ ».
> Filtrer les lignes vides et les retweets
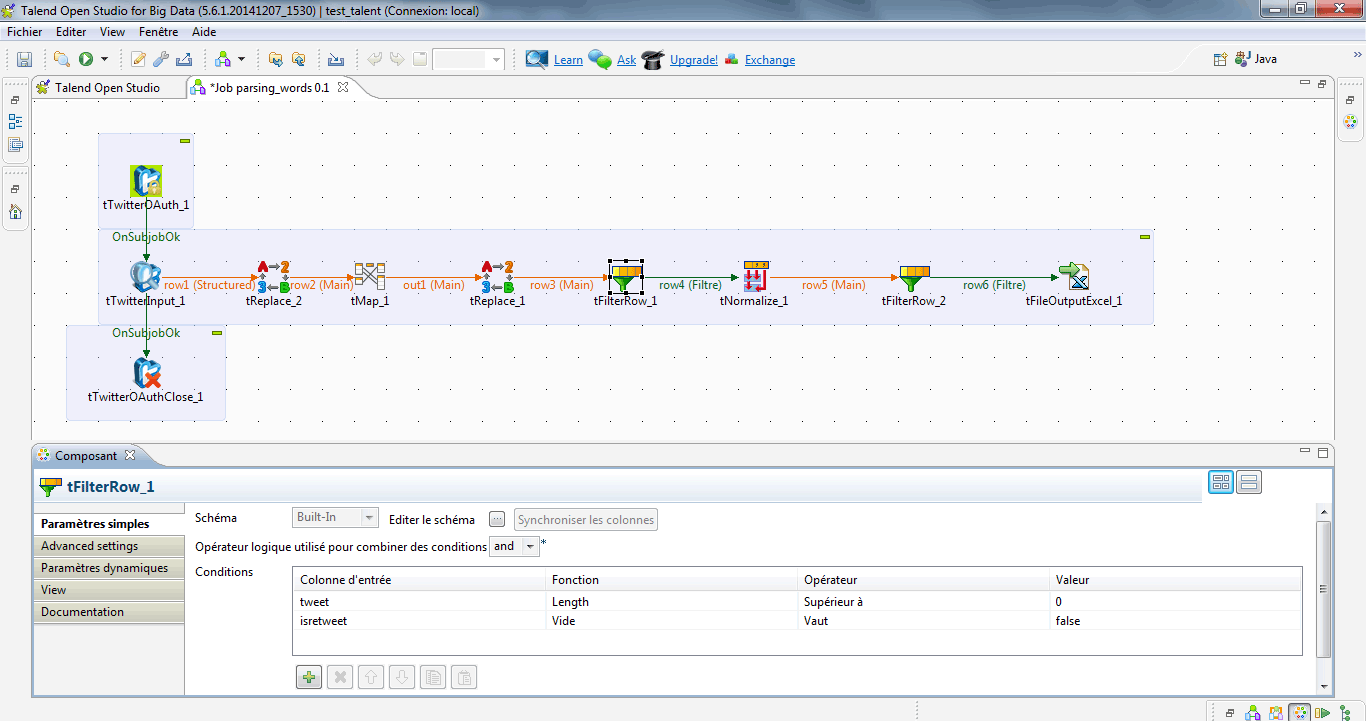
Afin de ne pas polluer ma future analyse de fréquence avec des doublons engendrés par les retweets, j’utilise la fonction tFilterRow de cette manière :
– je supprime les tweets vides
– je ne retiens que les tweets pour lesquels le champ isretweet est « faux »
> Découper les tweets en mots
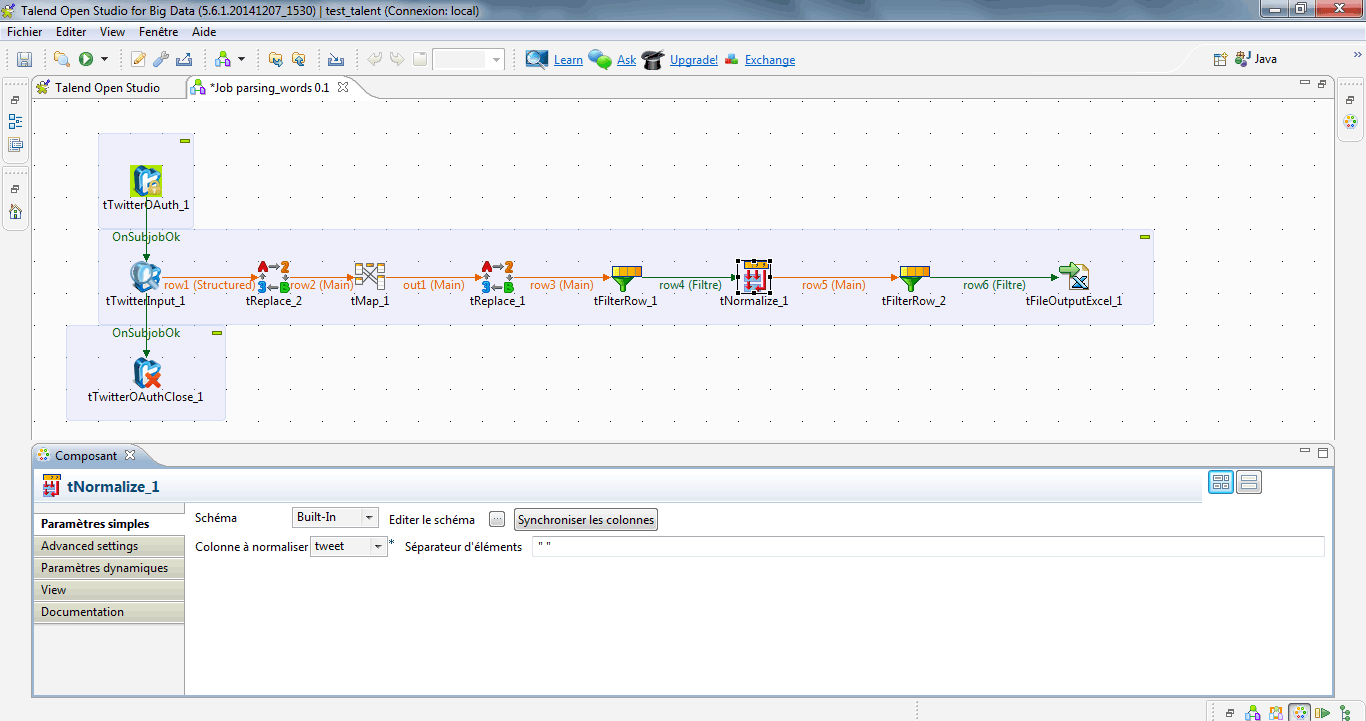
A l’aide du composant tNormalize, je découpe mes tweets en mots, à chaque fois que le composant rencontre un espace.
> Supprimer les mots de moins de 4 caractères
Afin d’éviter de surcharger mon fichier exporté – et plus tard complexifier mon analyse – je supprime les mots de moins de 4 caractères (ex : le, la, les, de, du etc.), à l’aide du composant tFilterRow.
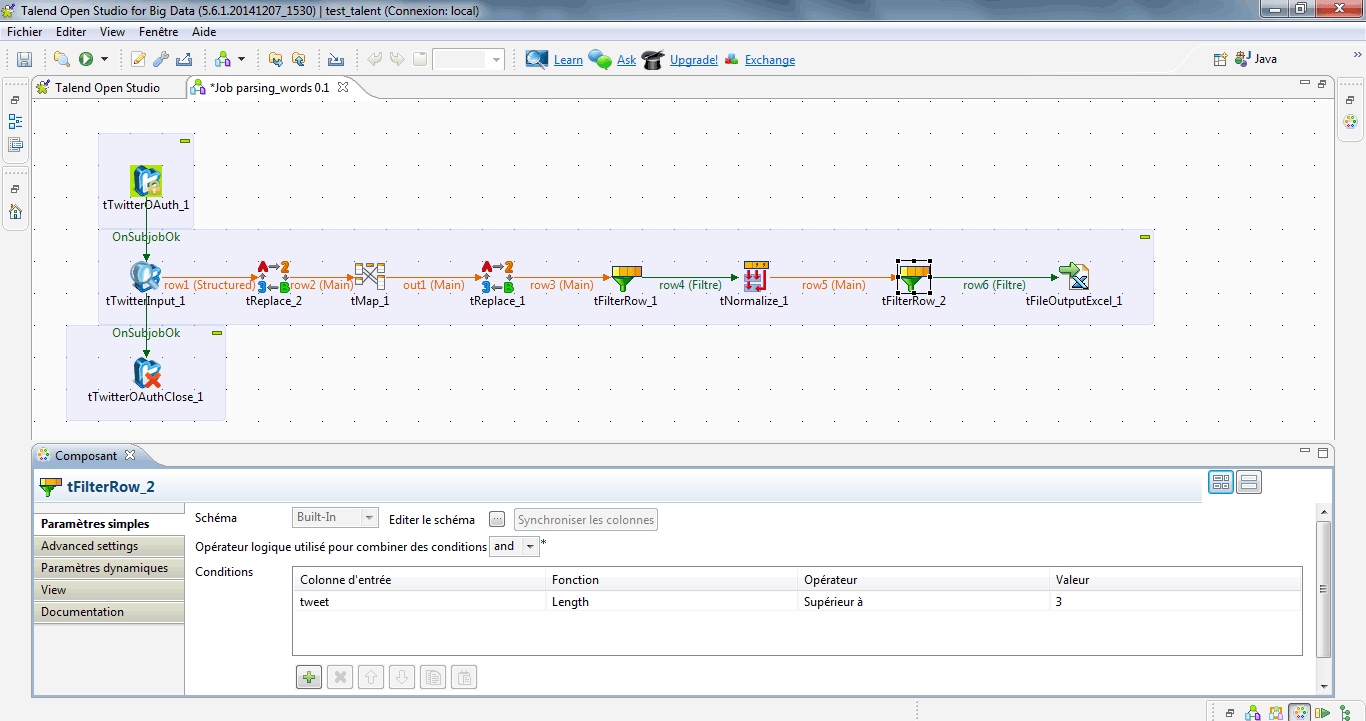
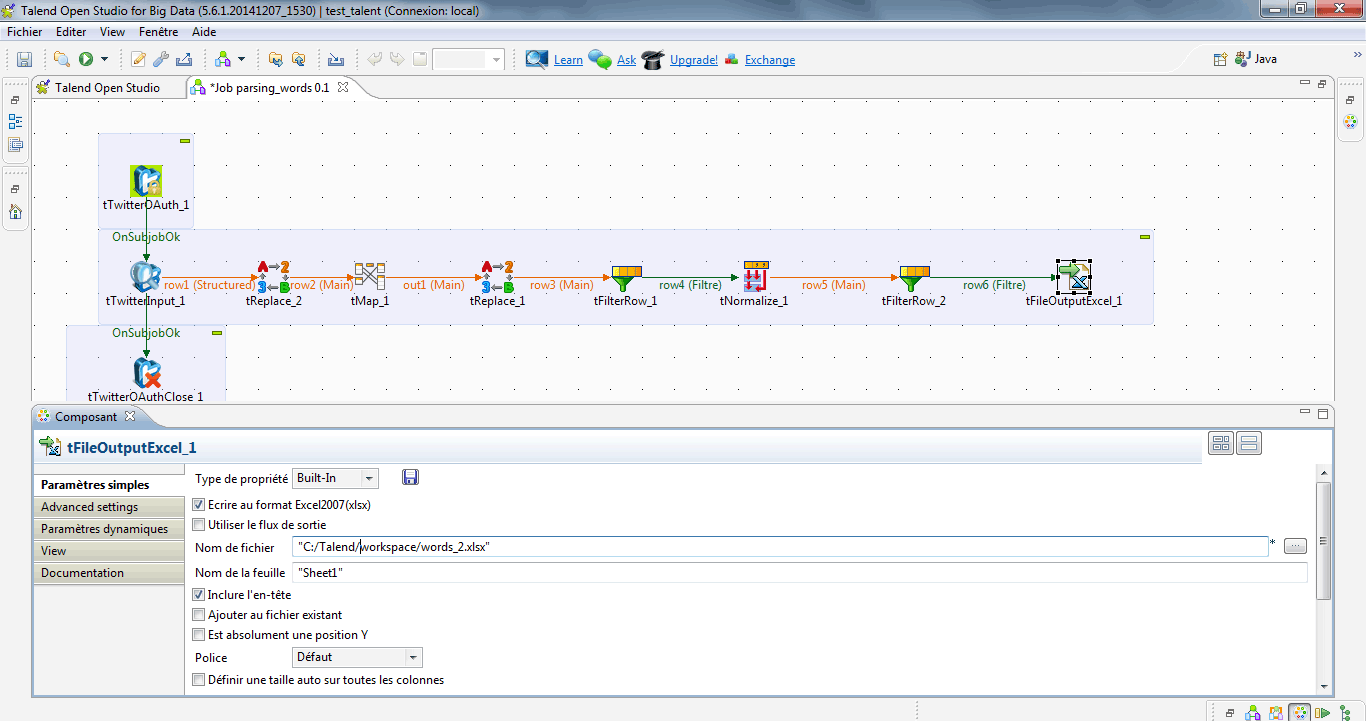
> Exporter le fichier
Enfin, la dernière étape consiste à exporter les résultats sous un fichier Excel. Le nombre de ligne pouvant être très grand, je choisis un fichier au format xlsx et d’inclure les entêtes. Il serait même judicieux d’utiliser le composant tFileOutputDelimited pour exporter au format CSV.
A vous de jouer !!! Après cela, il ne reste plus qu’à analyser les données !
Une réponse sur « Tutoriel – préparer un corpus à une analyse de fréquence avec Talend »
[…] analyse bonus, j’ai découpé tous mes tweets en mots à l’aide de Talend afin de produire une analyse de fréquence. On pourrait appliquer une méthode plus fine à l’aide de l’outil Iramuteq (voir la […]