
Le précédent tutoriel expliquait comment constituer un dataset de tweets et le formater pour le rendre facilement manipulable. Nous allons expliquer comment exploiter partiellement ces données pour construire un tableau de bord. Pour cela, nous allons nous appuyer sur une solution propriétaire, Tableau desktop, développée par Tableau Software. L’outil étant payant, il est toutefois possible d’exploiter les données sur des solutions plus communes telles que Google fusion tables ou directement dans Excel.
Pour cet exemple, j’ai constitué un dataset de tweets concernant le festival Rock en Seine. Le 3 mars 2015, l’organisation du festival a révélé une partie de sa programmation. Nos analyses vont chercher à répondre à plusieurs questions :
- cette annonce a-t-elle fait du « bruit » ?
- qui a pris la parole ?
- quels sont les sujets qui ont retenu l’attention ?
-
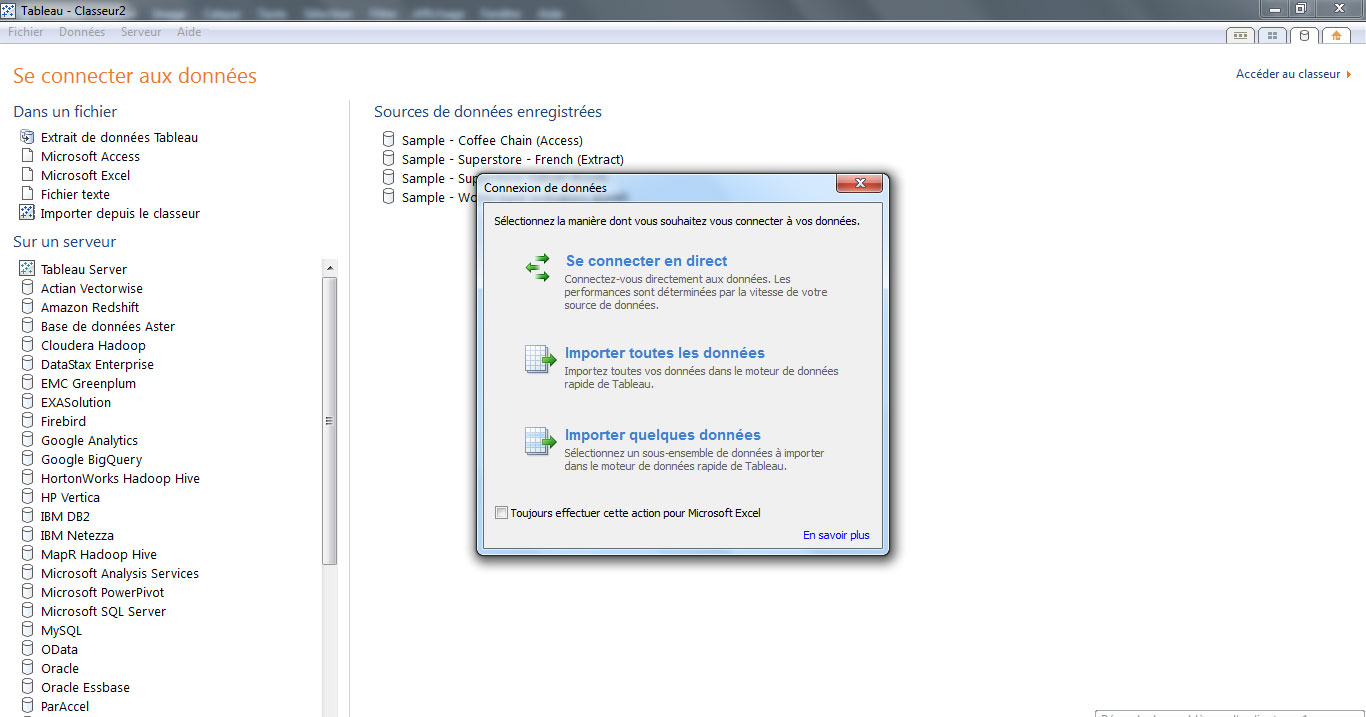
Se connecter aux données
A l’ouverture de Tableau Desktop, j’importe mes données en choisissant « Microsoft Excel » en source. Je valide la création d’un projet puis j’importe l’ensemble des données (non recommandé si votre dataset est très volumineux).
-
Reformater les données
Tableau a placé nos différents champs en fonction de dimensions et de mesures. Néanmoins, nous allons devoir reformater les données pour pouvoir les manipuler aisément.
Taverny > Utiliser les champs id et user_id pour effectuer des comptages de tweets et d’utilisateurs
Nous allons dupliquer les champs id et user_id et leur attribuer une agrégation par défaut. Pour cela, je clique bouton-droit sur le champ, et je sélectionne « Dupliquer ».
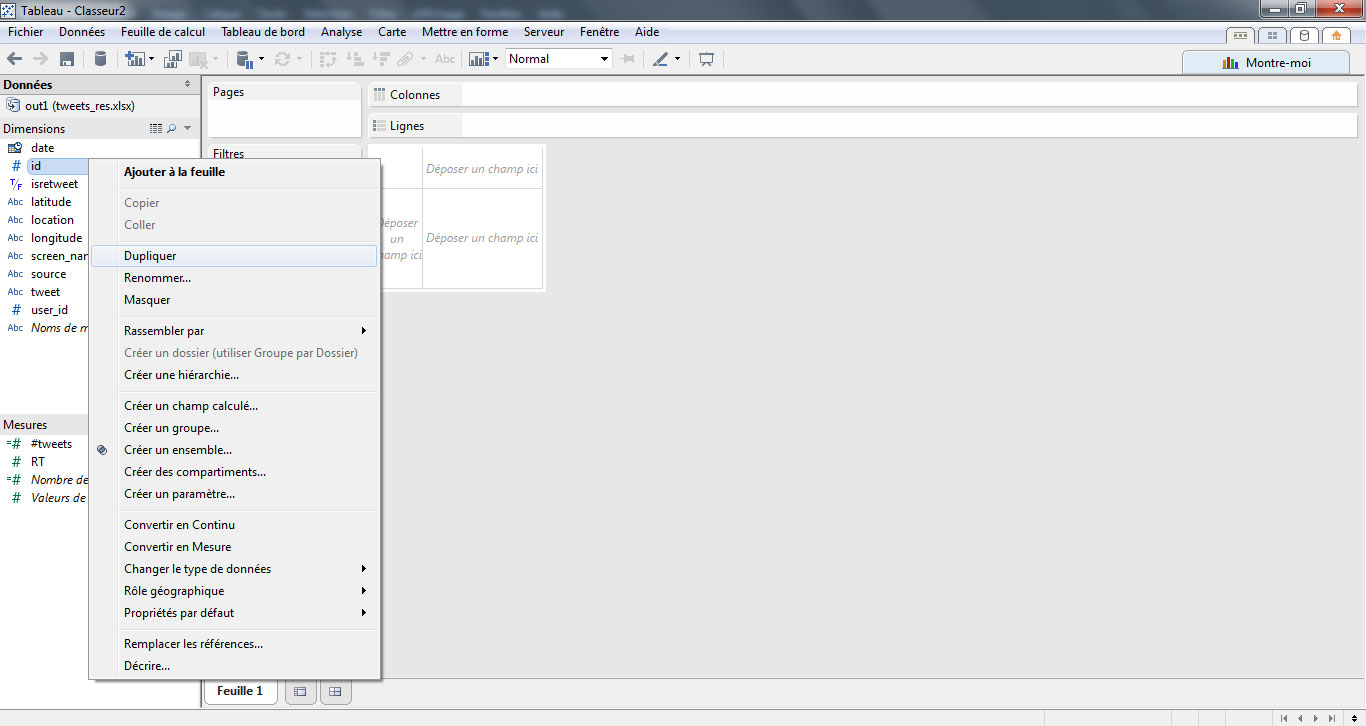
Puis, j’effectue un glisser-déposer pour placer ce nouveau champ au sein de mes mesures. Je renomme le champ avec un nom plus explicite (ex : #tweets). Je change la méthode d’interprétation des données, en faisant bouton-droit > propriétés > agrégation > total (distinct).
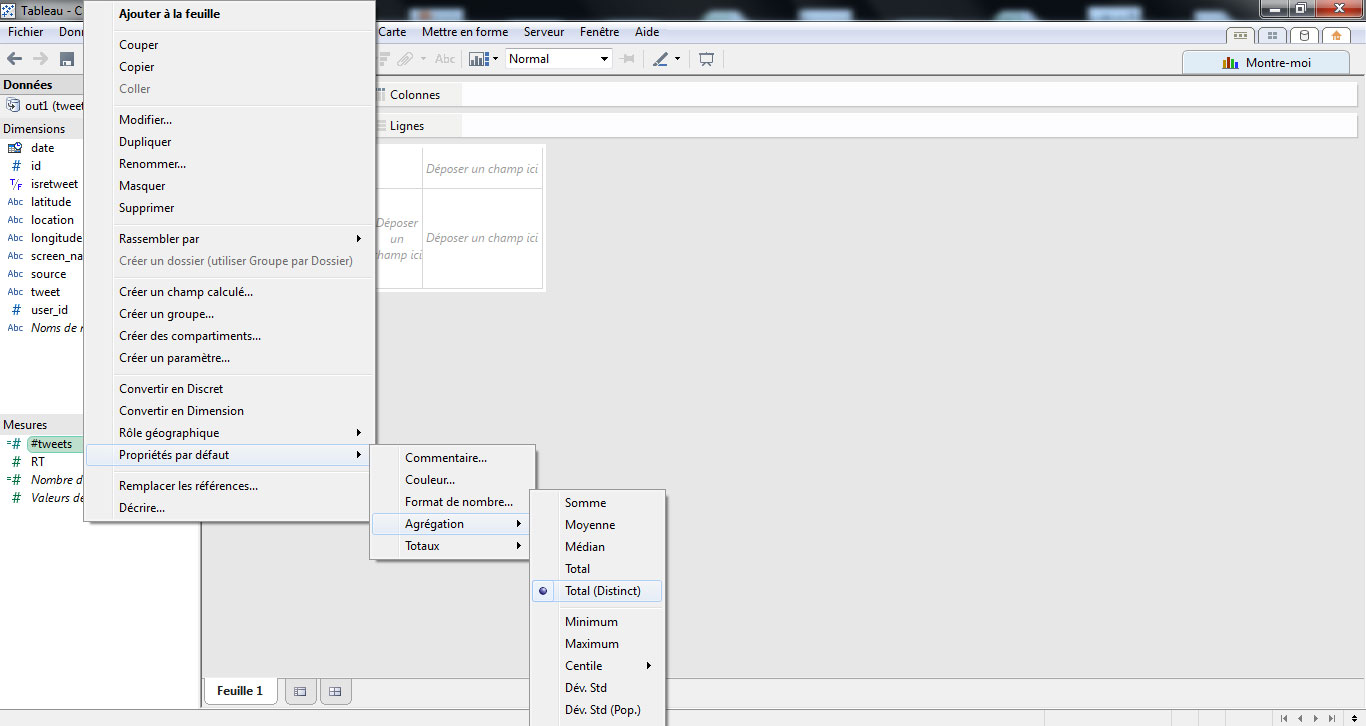
Je réitère la procédure avec le champ user_id.
calais rencontre etudiant > Attribuer un rôle géographique aux champs latitude et longitude
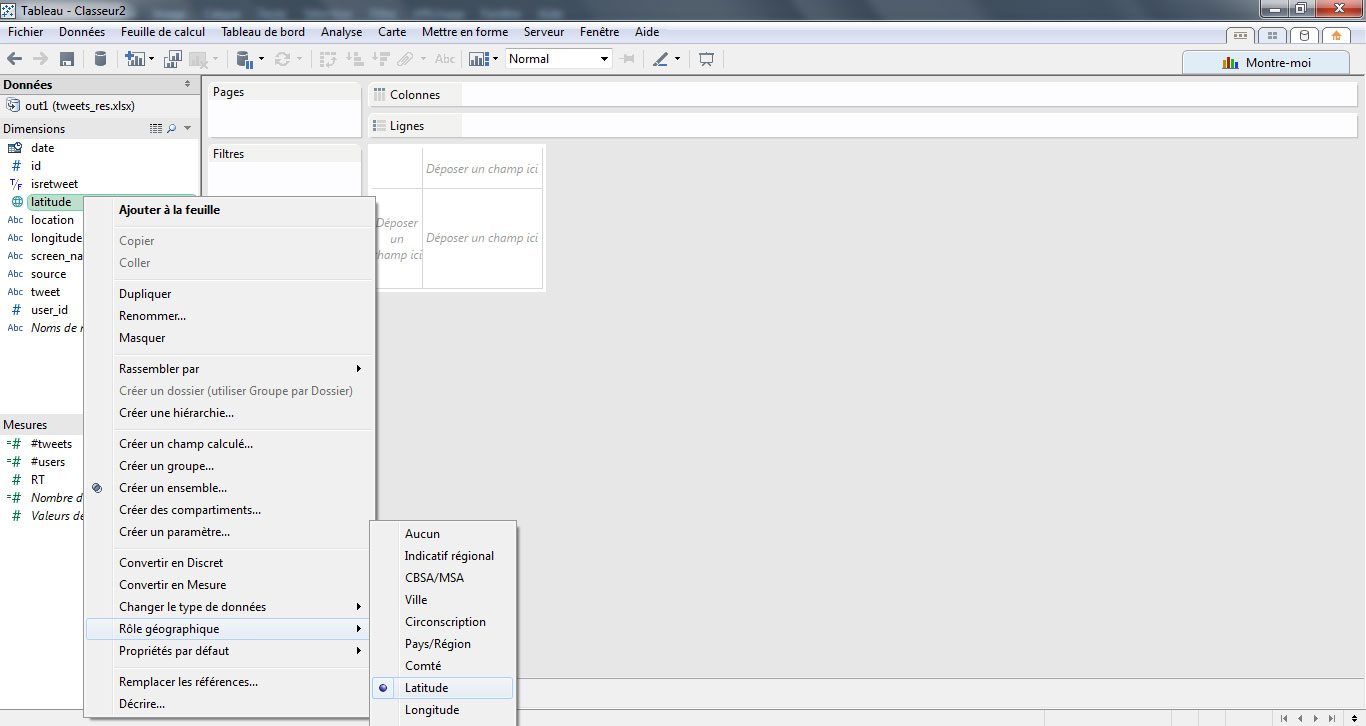
Les champs latitude et longitude sont actuellement considérés comme des chaines de caractères, nous allons leur attribuer un rôle géographique. La première étape consiste à changer le type de données en sélectionnant « Nombre ».
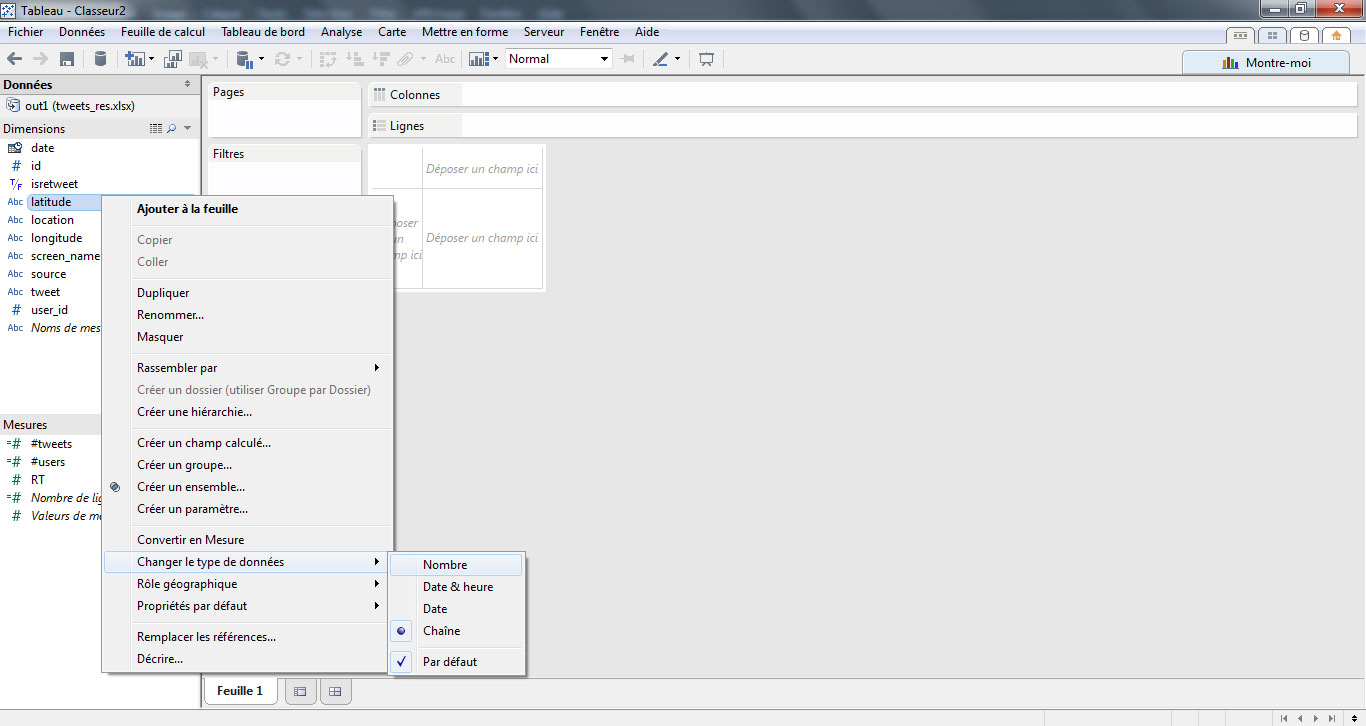
Puis, on attribue un rôle géographique en sélectionnant « latitude » ou « longitude ».
Pulong Santa Cruz > Analyser l’évolution temporelle des tweets
Réalisons un premier graphe, présentant le nombre de tweets dans le temps. Pour cela, je place mon champ « date » en colonne, et mon nombre de tweets (#tweets) en ligne. La représentation n’est pas adaptée. Donc, il me faut modifier la granularité du champ « date » et choisir une représentation sous forme de « courbe de tendance ».
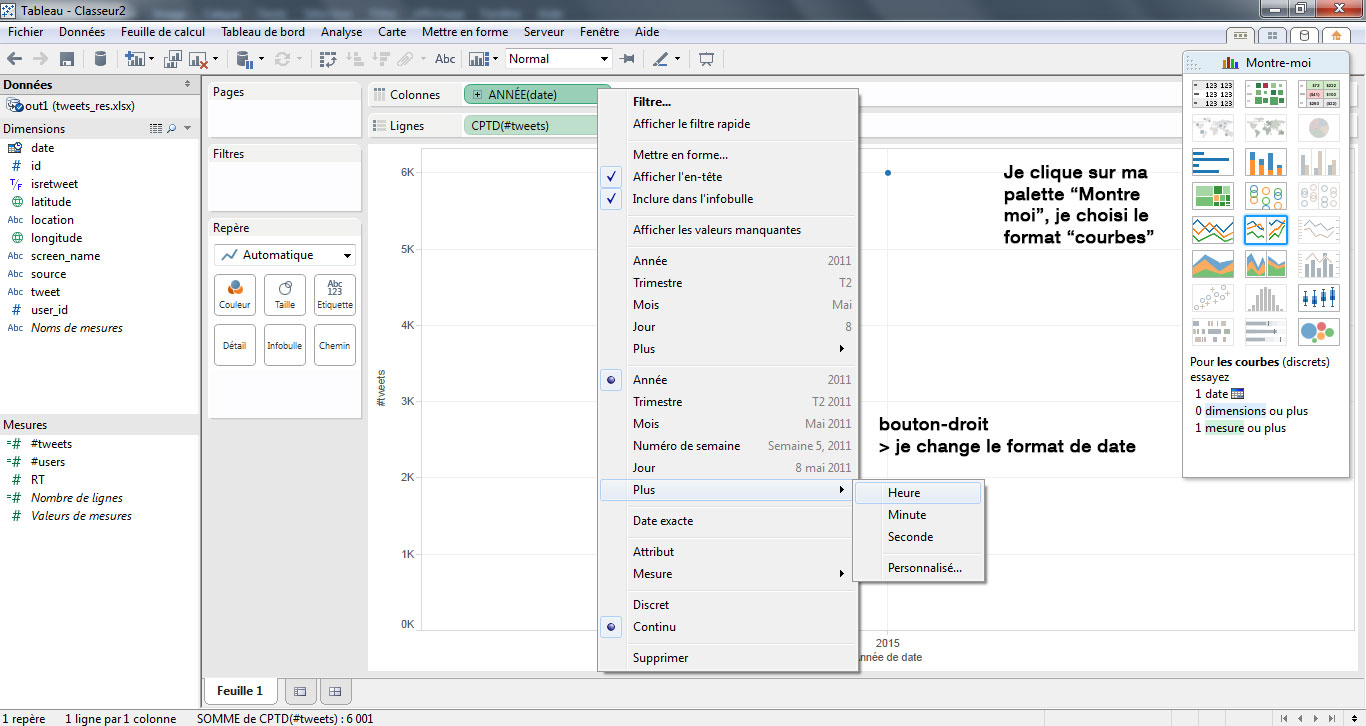
Un pic de tweets apparait, mais ne m’apporte pas suffisamment d’informations pour distinguer la nature des messages. Je vais donc utiliser le champ « isretweet » pour distinguer le volume de retweets des messages « originaux » en l’appliquant sur le paramètre « Couleur ». J’obtiens deux courbes, l’une représentant les tweets originaux, l’autre les retweets.
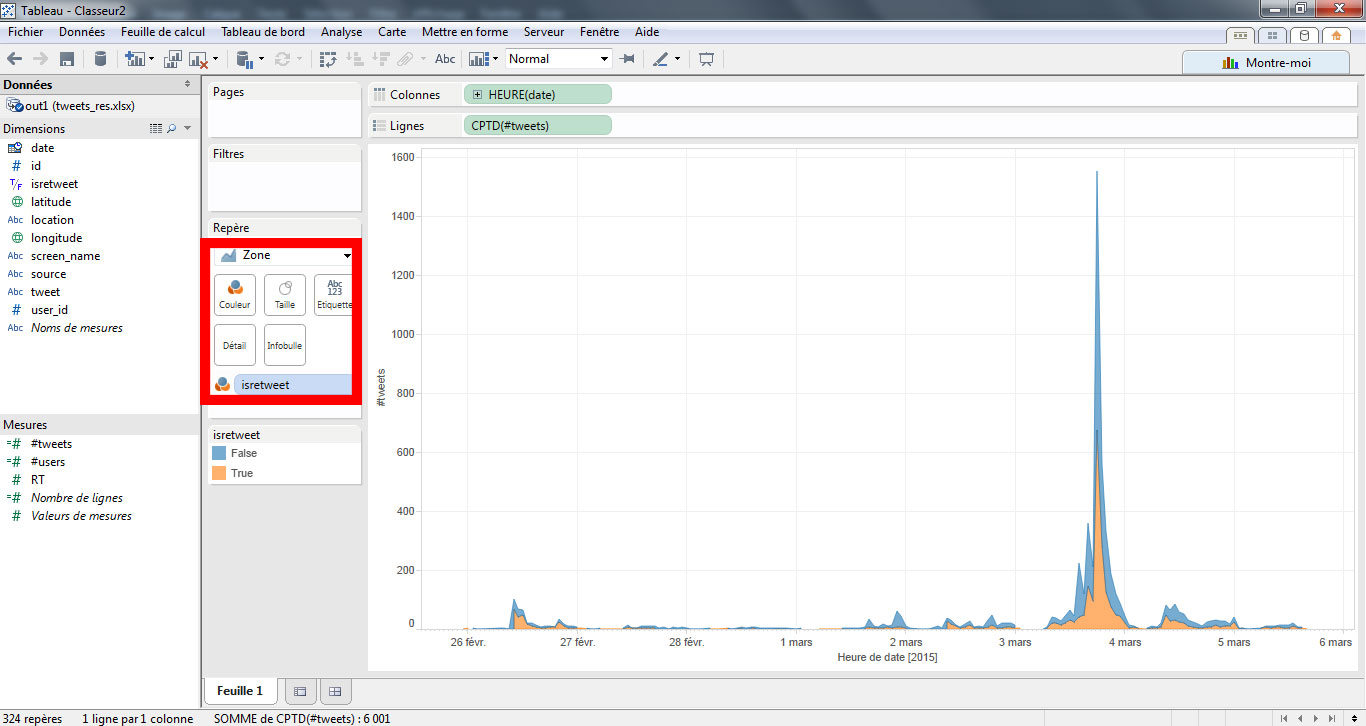
Je modifie une nouvelle fois la représentation pour choisir le format « graphique par aires ». J’ajoute ensuite le champ « Date » en filtre. Je sélectionne le format « plage de dates » et je vais sélectionner la période où l’on observe le plus gros pic (en l’occurrence du 3 au 5 mars).
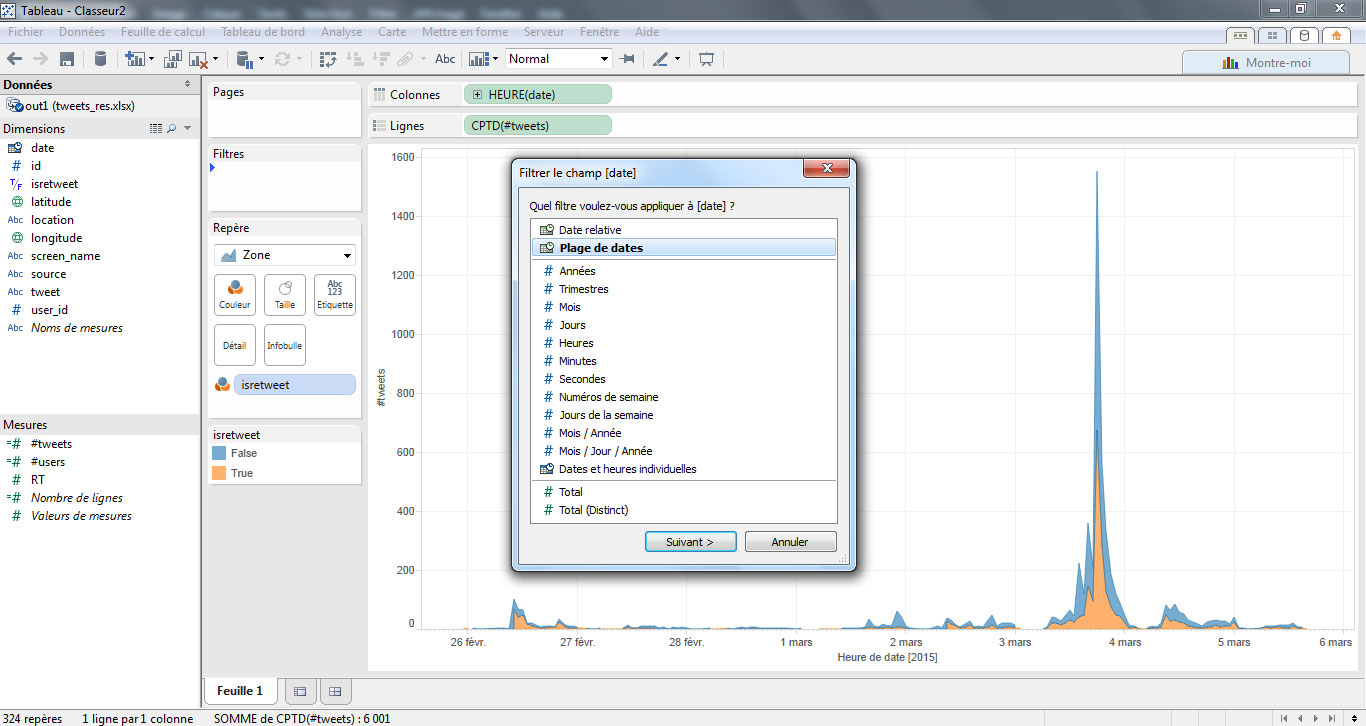
Enfin, je clique bouton-droit sur mon filtre et je choisis « Afficher le filtre rapide » pour facilement mettre à jour les données lorsque je souhaite me focaliser sur une période. Voici le graphe obtenu au final :
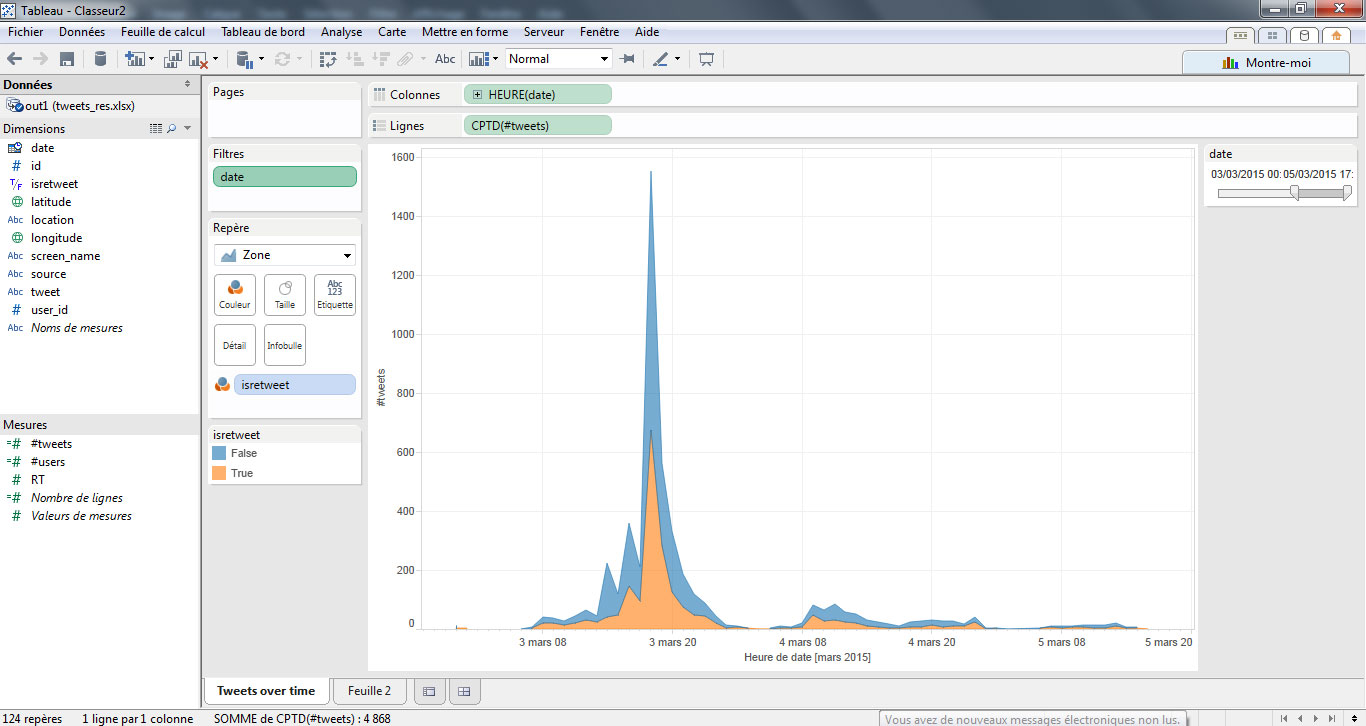
On peut réaliser le même graphique en substituant le nombre de tweets au nombre d’utilisateurs pour mesurer l’évolution des acteurs en jeu.
Analyse : on observe un premier pic, à la date du 28 février. Il s’agit de la période de ‘teasing’ enclenchée par l’organisation du festival qui annonce que les premières têtes d’affiches seront révélées le 3 mars. Puis, le 3 mars, on observe un large pic correspondant à cette annonce. Le lendemain, on identifie un nombre plus important qu’à l’habitude ; il s’agit des retombées presse et du commentaire des futurs festivaliers.
> Quels groupes ont retenu l’attention ?
Pour aller plus loin, on peut analyser cette courbe de tendance en la segmentant en fonction d’un mot-clé. Trois choix s’offrent à nous :
– utiliser un filtre et s’en servir comme moteur de recherche
– utiliser un filtre avec la fonction « contains » pour effectuer une recherche stricte sur un ou plusieurs artistes
– créer un paramètre passé dans la fonction « contains » pour sélectionner un artiste parmi une liste
> ajouter un moteur de recherche
Il s’agit de la méthode la plus simple, mais qui ne peut s’appliquer qu’à un dataset limité (sinon le temps de requête sera trèèèèèèès long). Je clique bouton-droit sur le champ tweet puis « afficher en tant que filtre rapide ».
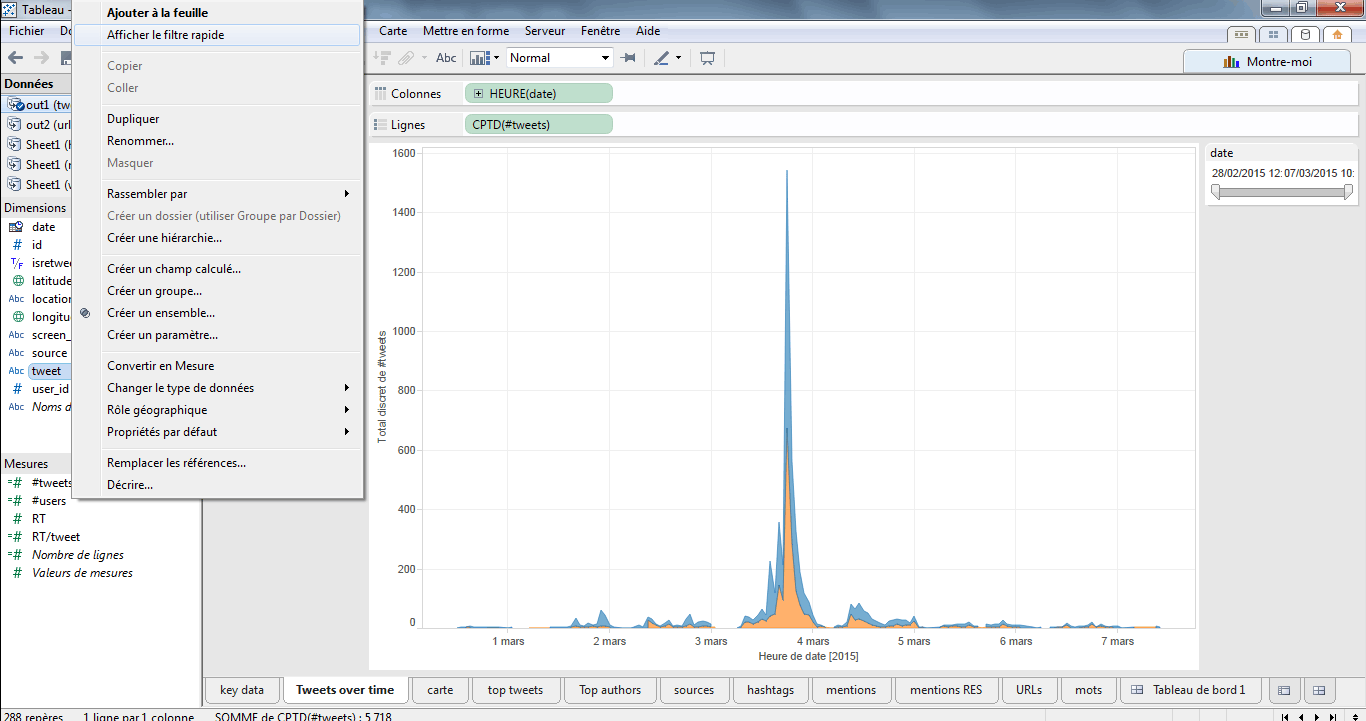
Puis, sélectionner le format de filtre « recherche générique ».
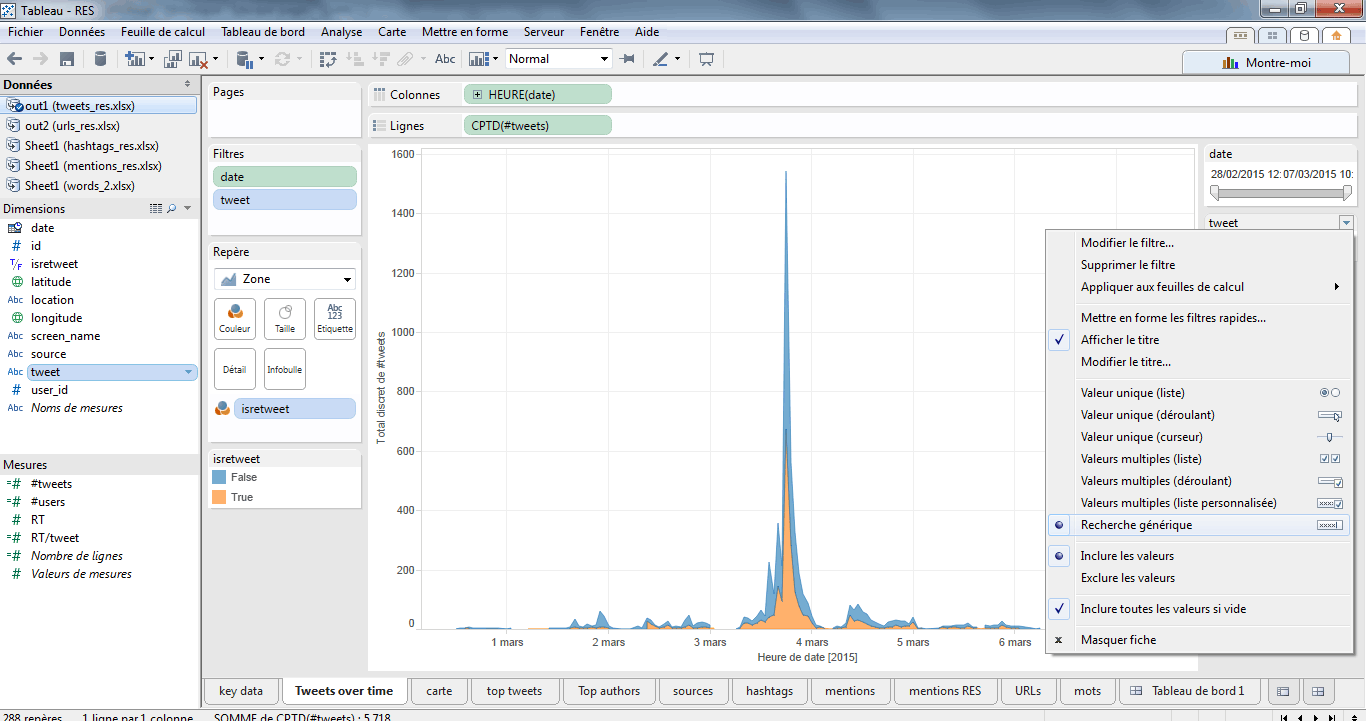
Enfin, il ne reste plus qu’à taper le nom d’un artiste, ou n’importe quel autre mot-clé, pour mettre à jour la courbe.
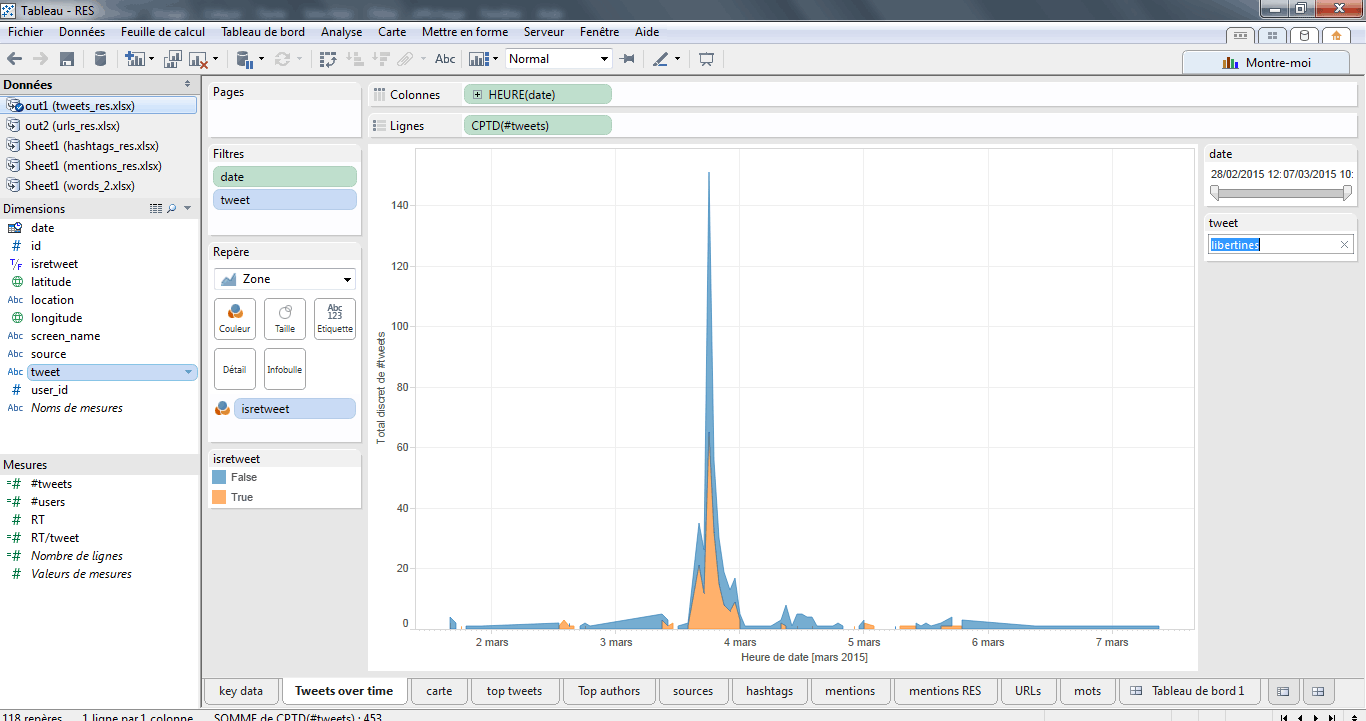
> utiliser un filtre avec la fonction « contains »
Pour des datasets plus volumineux, il faudra créer un champ calculé. Pour cela, je clique bouton-droit parmi mes dimensions et je sélectionne « créer un champ calculé ». Une fenêtre apparait. Je donne un nom à ma fonction (ex : « contient_libertines ») et je tape ma fonction.
En l’occurence, nous utilisons la fonction « contains » et nous allons chercher au sein des tweets le sème « libertines ». La fonction étant sensible à la casse, nous allons d’abord passer les tweets en minuscules à l’aide de la fonction lower(). Je tape donc : contains(lower(), « libertines »)
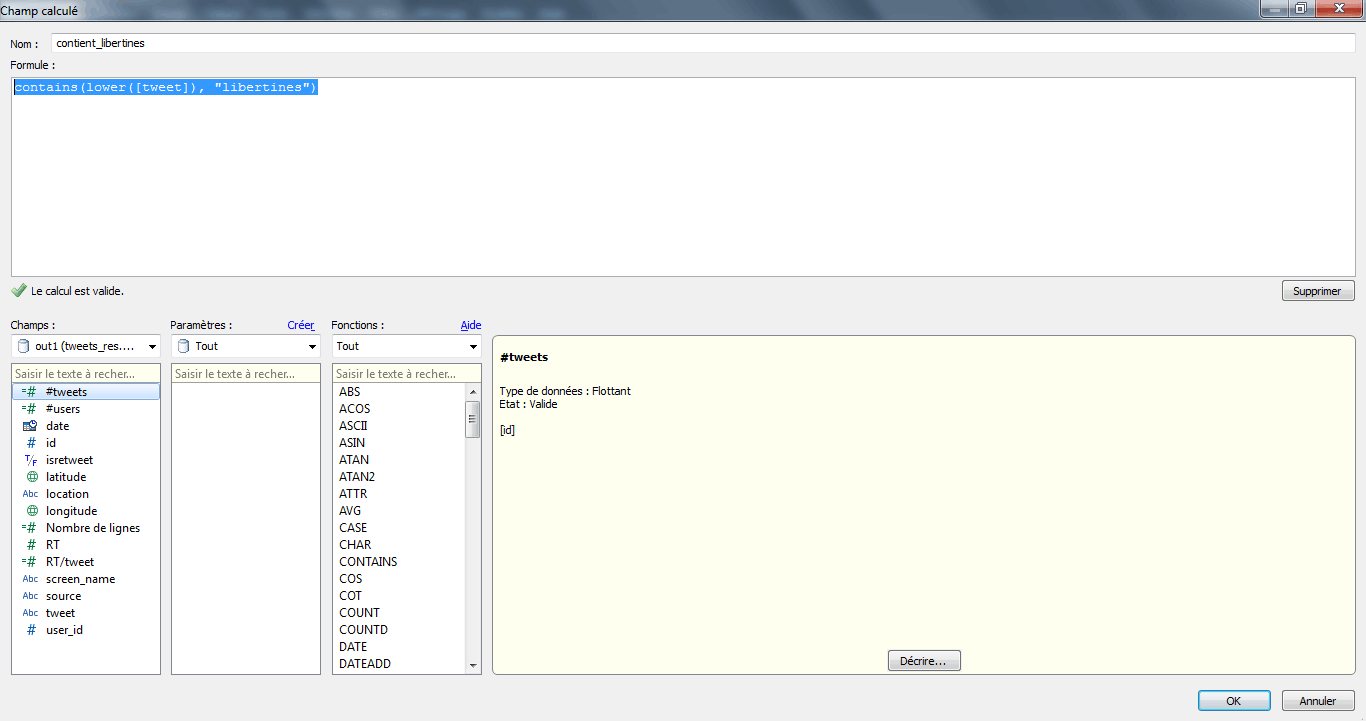
Je n’ai plus qu’à afficher le filtre rapide et sélectionner la valeur « vrai » pour mettre à jour le graphique.
> Créer un paramètre pour sélectionner un artiste parmi une liste.
Afin d’éviter de multiplier les champs calculé, je peux créer une liste de mots-clés que je passerais en paramètre de mon filtre. Pour cela, je clique bouton-droit puis je sélectionne « créer un paramètre ».
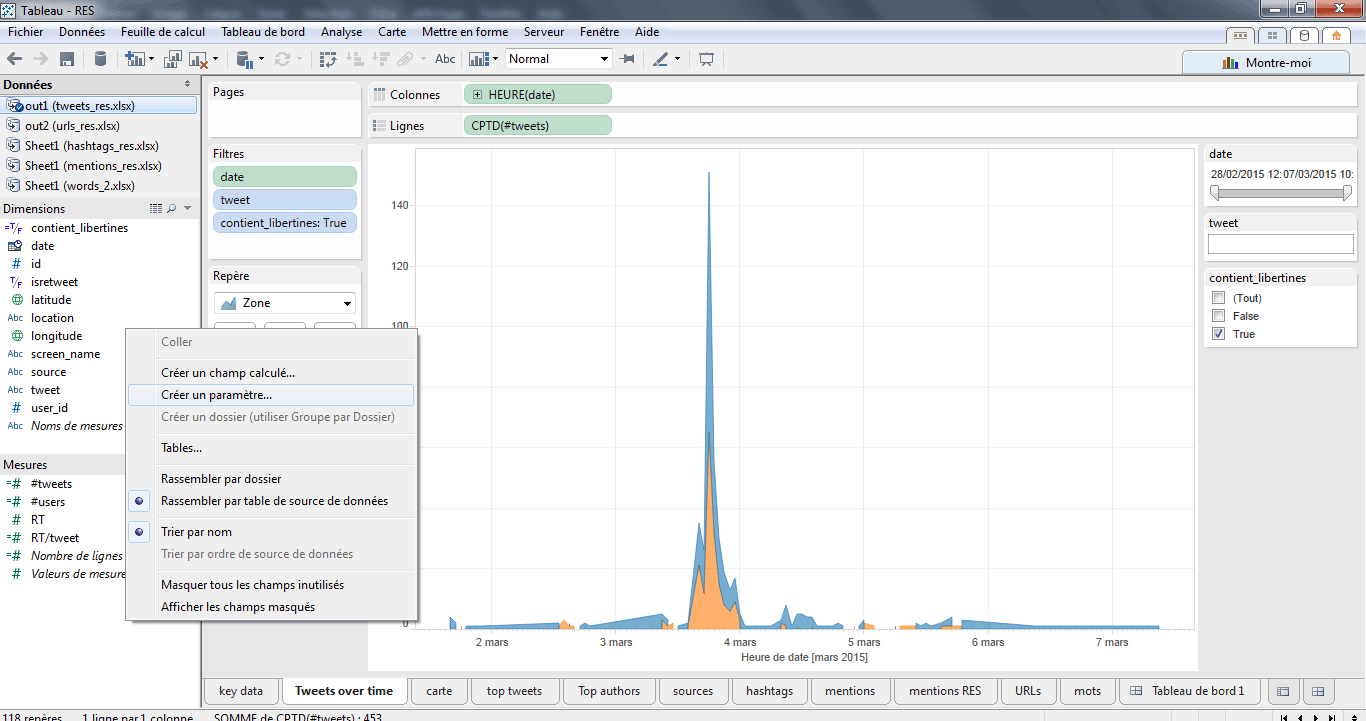
Une fenêtre apparait, je donne un nom à mon paramètres (groupes), je sélectionne « chaine » comme type de données et je constitue ma liste en indiquant les sèmes sur lesquels je souhaite effectuer un filtre.
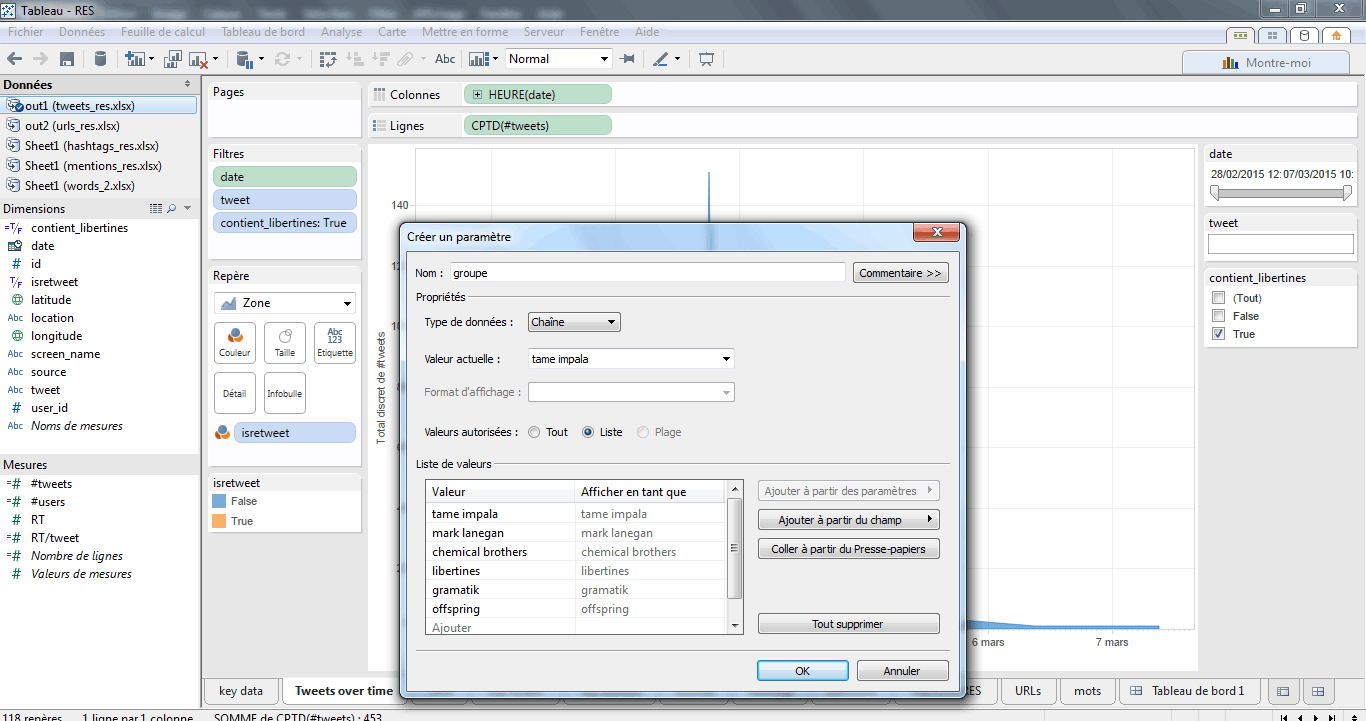
Une fois mon paramètre créé, il me faut modifier mon filtre contient_libertines. Je vais donc le renommer en « contient_param_groupes » et mettre à jour la formule. Je tape contains(lower(), [groupe])
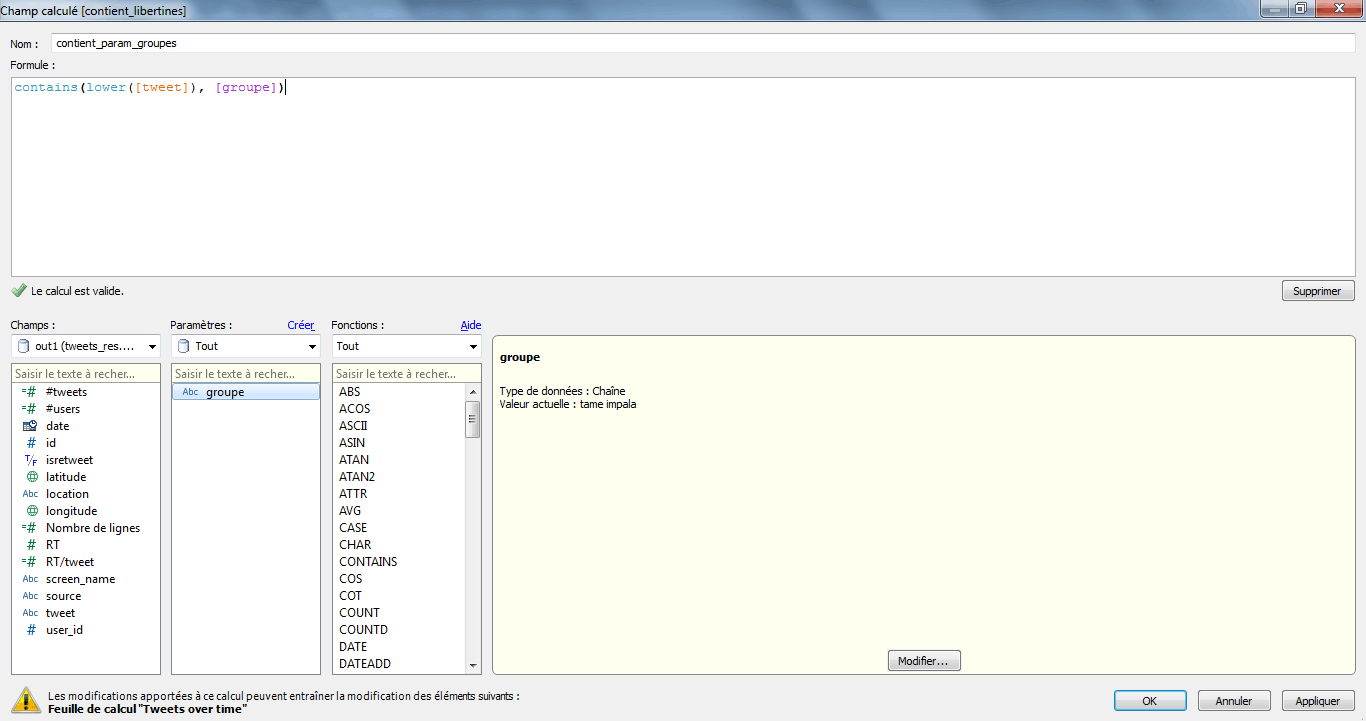
Il ne me reste plus qu’à afficher la commande de paramètre sur mon espace de travail en cliquant bouton-droit sur le paramètre ‘groupe’.
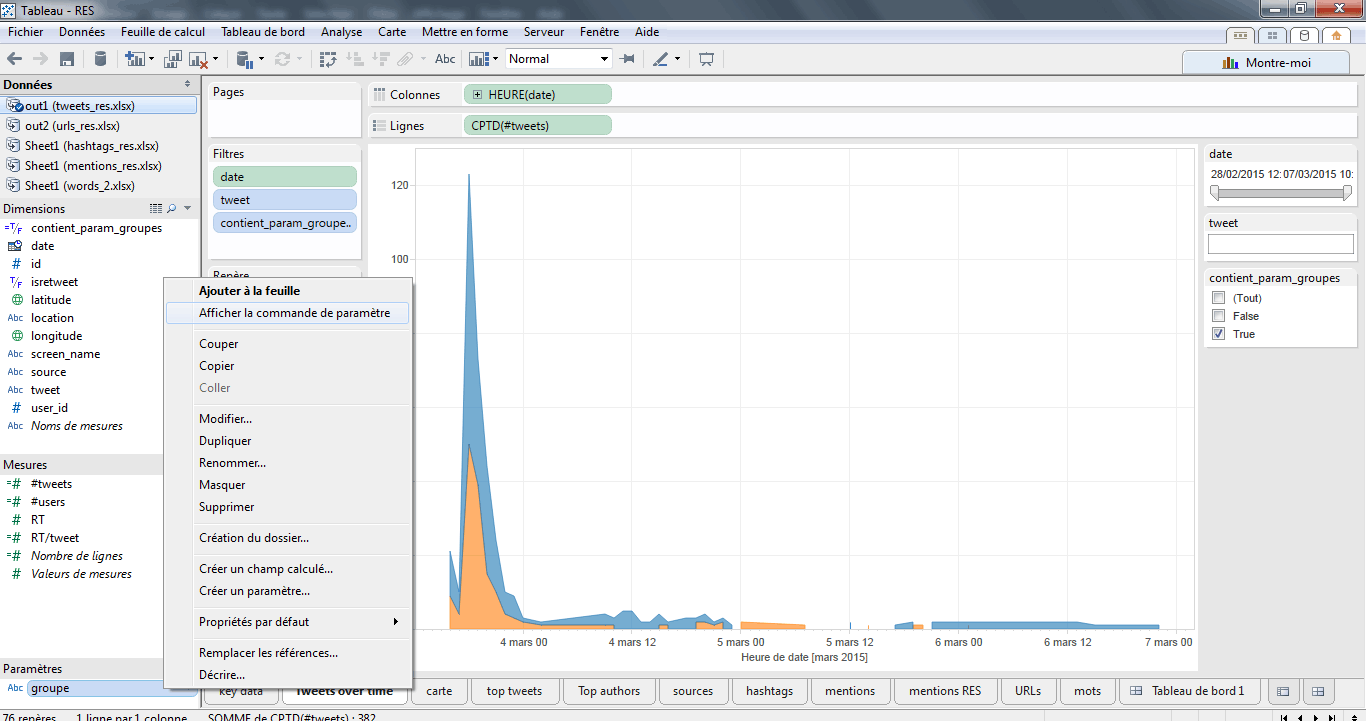
Je peux maintenant sélectionner dans un menu déroulant le nom du groupe avec lequel je souhaite filtrer les données.
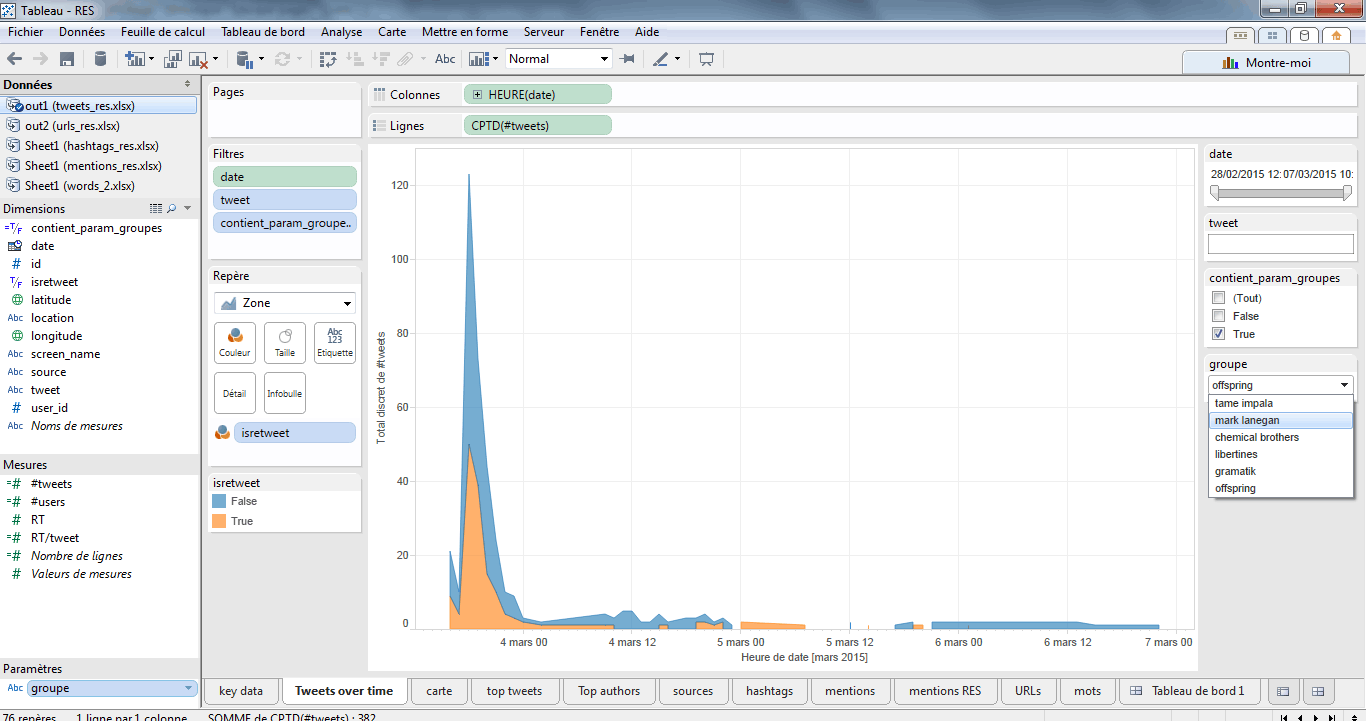
> Réaliser une cartographie des tweets
Tous les tweets ne contiennent pas de données de géolocalisation. Seul un faible pourcentage des utilisateurs acceptent volontairement de partager leurs coordonnées lors de la publication d’un message. Tableau Software permet de réaliser une carte à l’aide des champs « latitude » et « longitude ». Dans une nouvelle feuille, placez ces champs respectivement en lignes et colonnes, puis choisissez la visualisation « carte » dans la palette « Montre moi ».
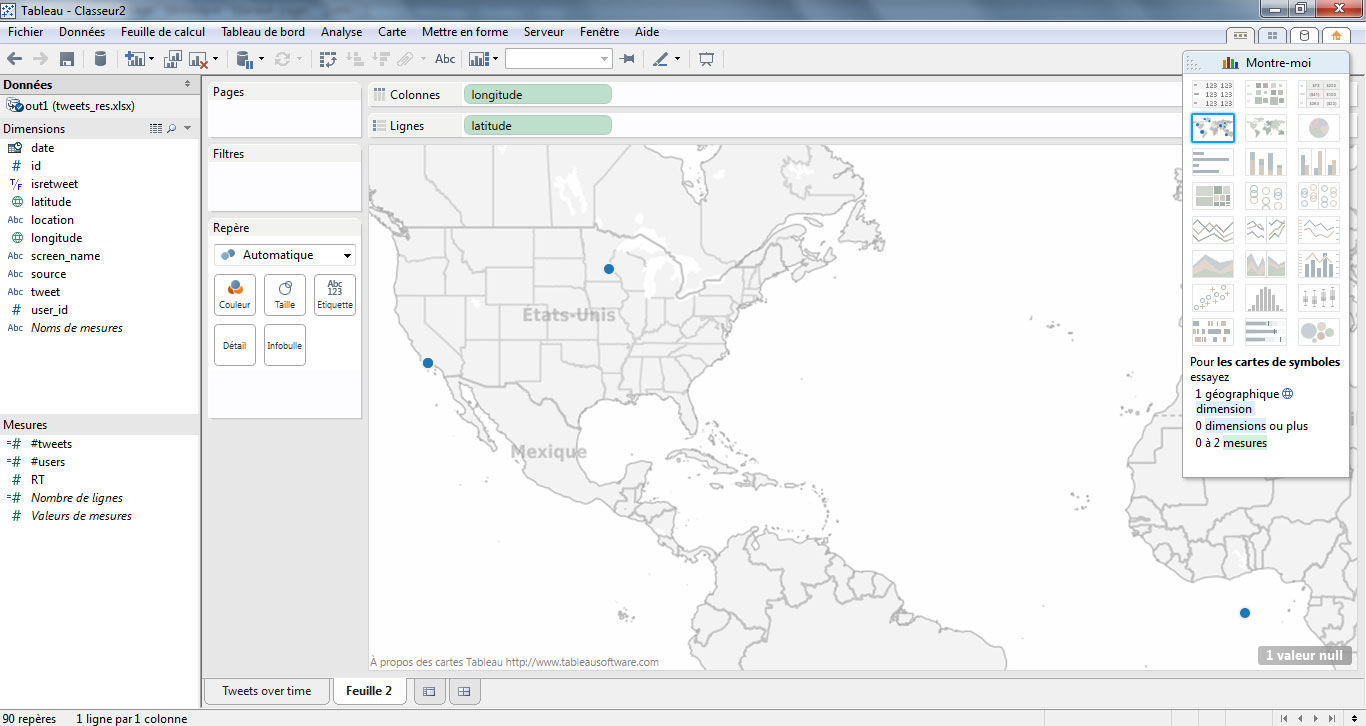
La plupart des messages étant localisés en France, focalisons-nous sur cette zone pour travailler la visualisation.
J’applique un filtre de date, comme précédemment, en sélectionnant la période du 3 mars au 5 mars. Puis, un filtre « isretweet » sur la valeur « false » de manière à n’afficher que les tweets « originaux ». J’affiche les filtres à proximité de mon graphe en cliquant bouton droit, puis « Afficher le filtre rapide ».
J’attribue ensuite la mesure « RT » à la taille de chaque point. Je modifie le format d’agrégation des données en sélectionnant « Maximum ».
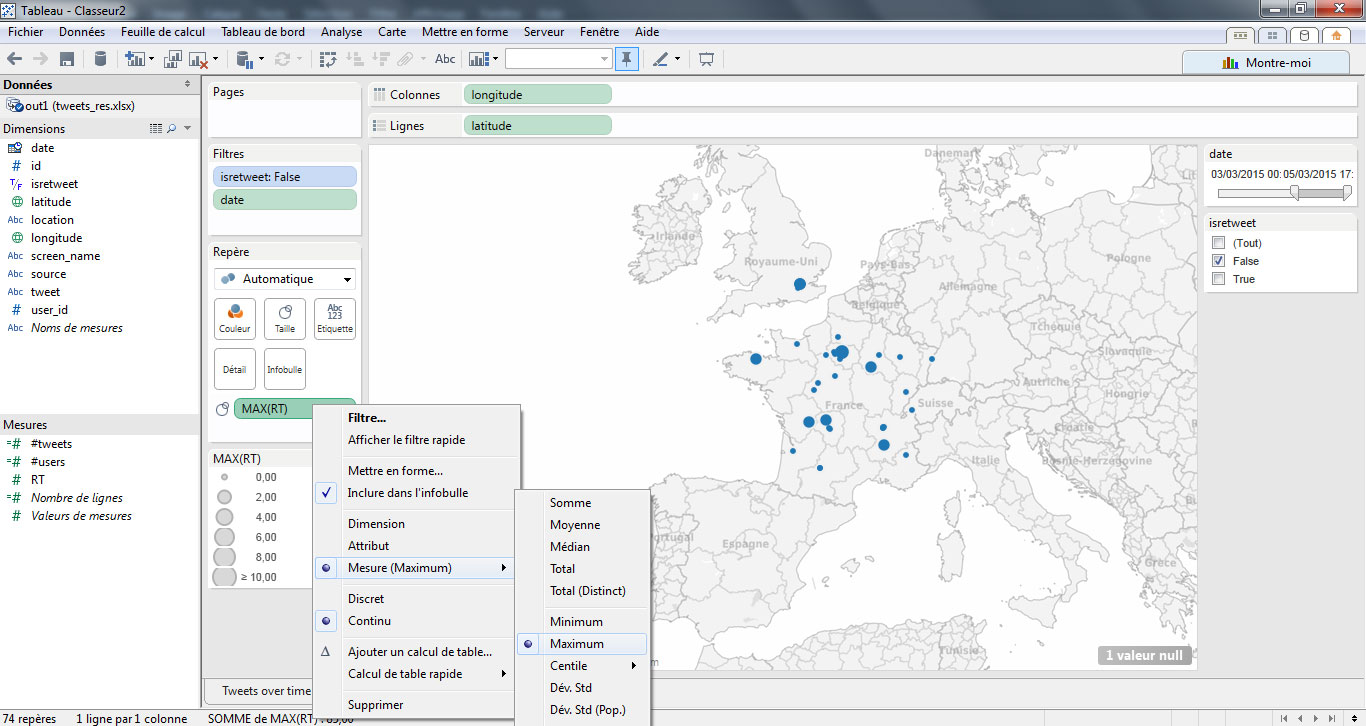
Ensuite, j’ajuste la taille des points en cliquant sur « modifier les tailles » dans la boite dédiée à la légende du graphique.
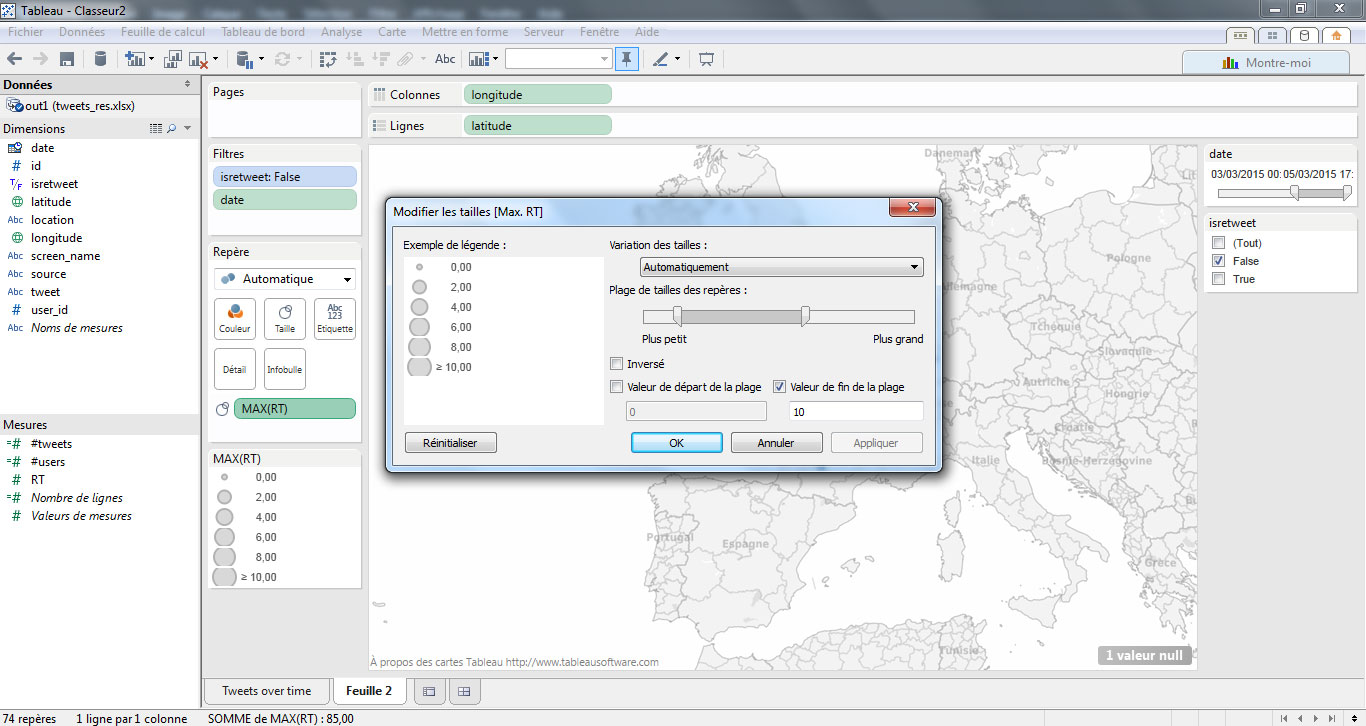
Etape finale, je rends ensuite plus esthétique et lisible ma carte en attribuant :
- le champ screenname à la couleur. Chaque point aura une couleur différente (sauf si un utilisateur a tweeté plusieurs fois).
- j’indique les infos essentielles en infobulles : le screenname de l’auteur, la date de publication du tweet, son contenu, son nombre de RT, etc.
- je place le texte du tweet en étiquette.
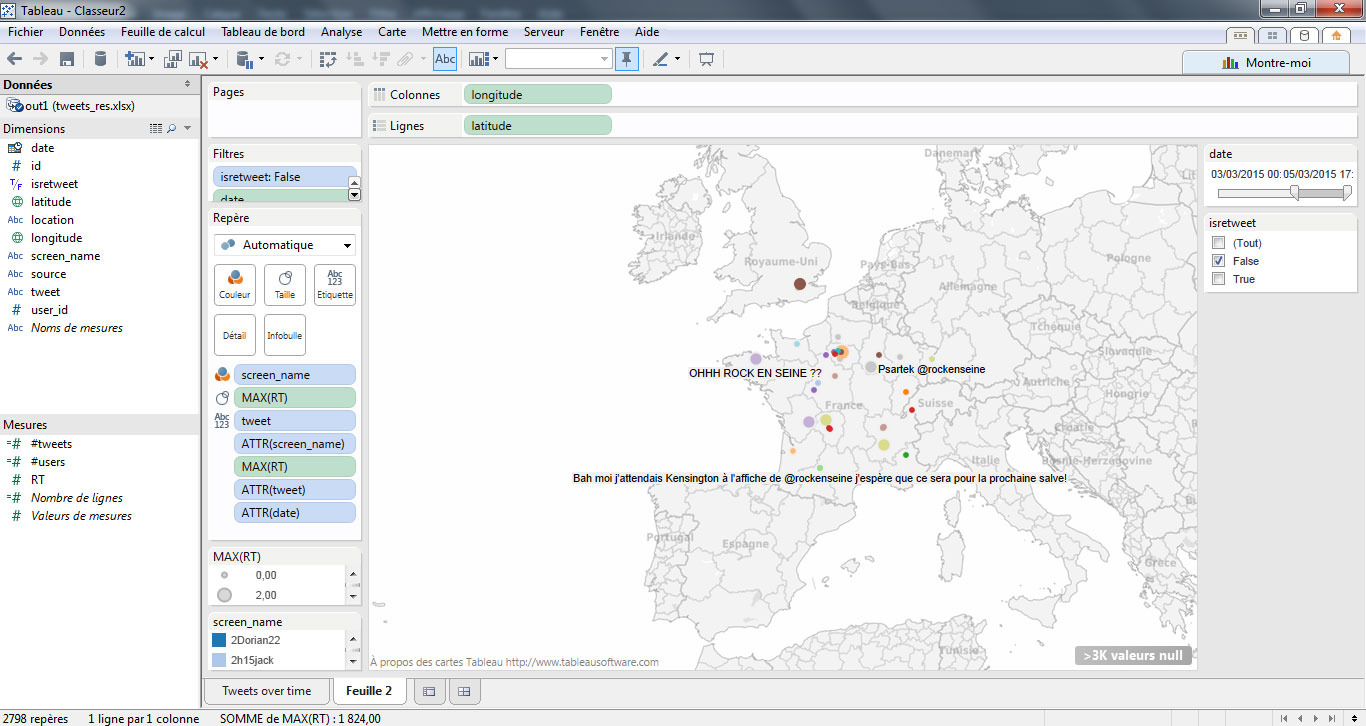
Voici le rendu.
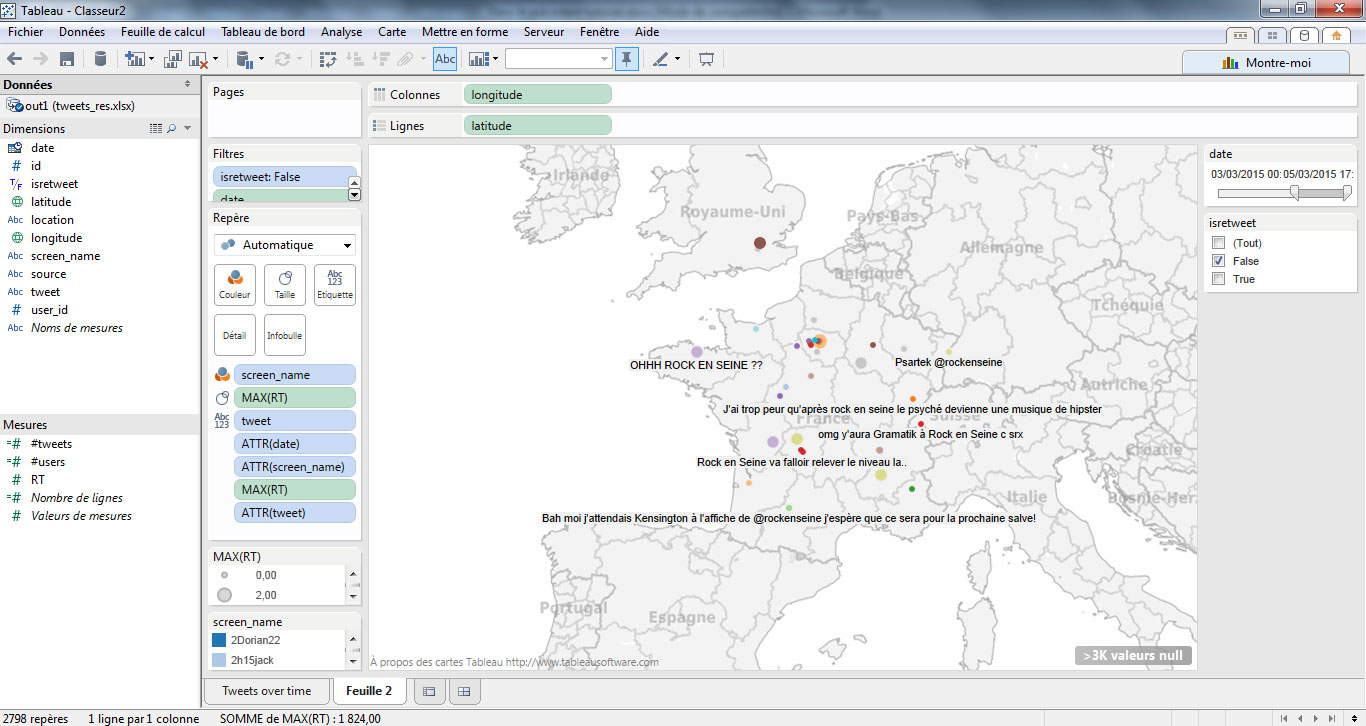
Analyse : Si quelques tweets ont été publiés depuis l’étranger, il s’agit la plupart du temps des groupes annoncés par l’organisation du fetival. L’annonce semble avoir fait réagir des usagers un peu partout en France, avec une légère suractivité en région parisienne.
> Le top des tweets
Maintenant, nous pouvons nous intéresser aux tweets ayant retenu le plus l’attention. Pour cela, réalisons une matrice présentant un classement des tweets, le nom de l’auteur, la date de publication et le nombre de RTs.
Les étapes sont les suivantes :
- je place le filtre isretweet = false. Nous nous intéressons uniquement aux contenus originaux.
- je place ma liste de tweets en lignes
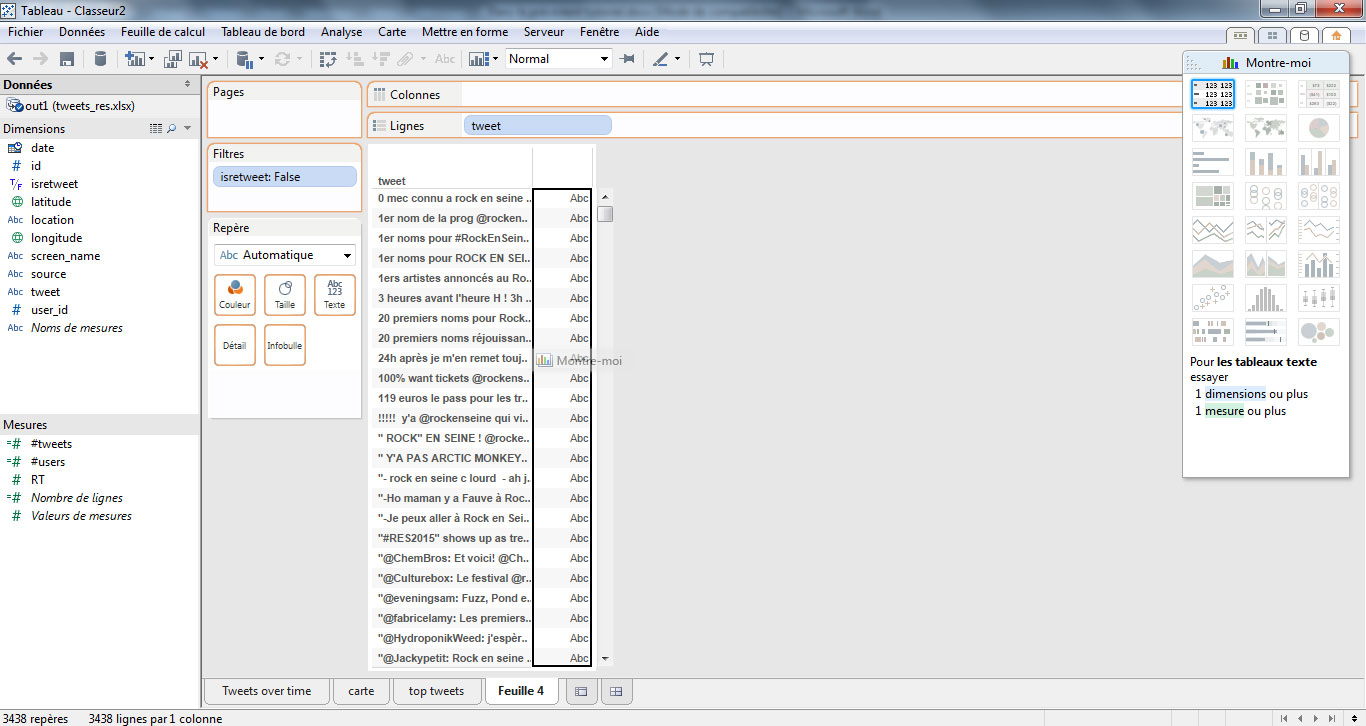
- je fais un glisser-déposer de ma mesure « RT ». Puis je m’assure que le format d’agrégation des données est bien « MAX ».
- Je trie ma liste de manière décroissante grâce à l’icône dédié.
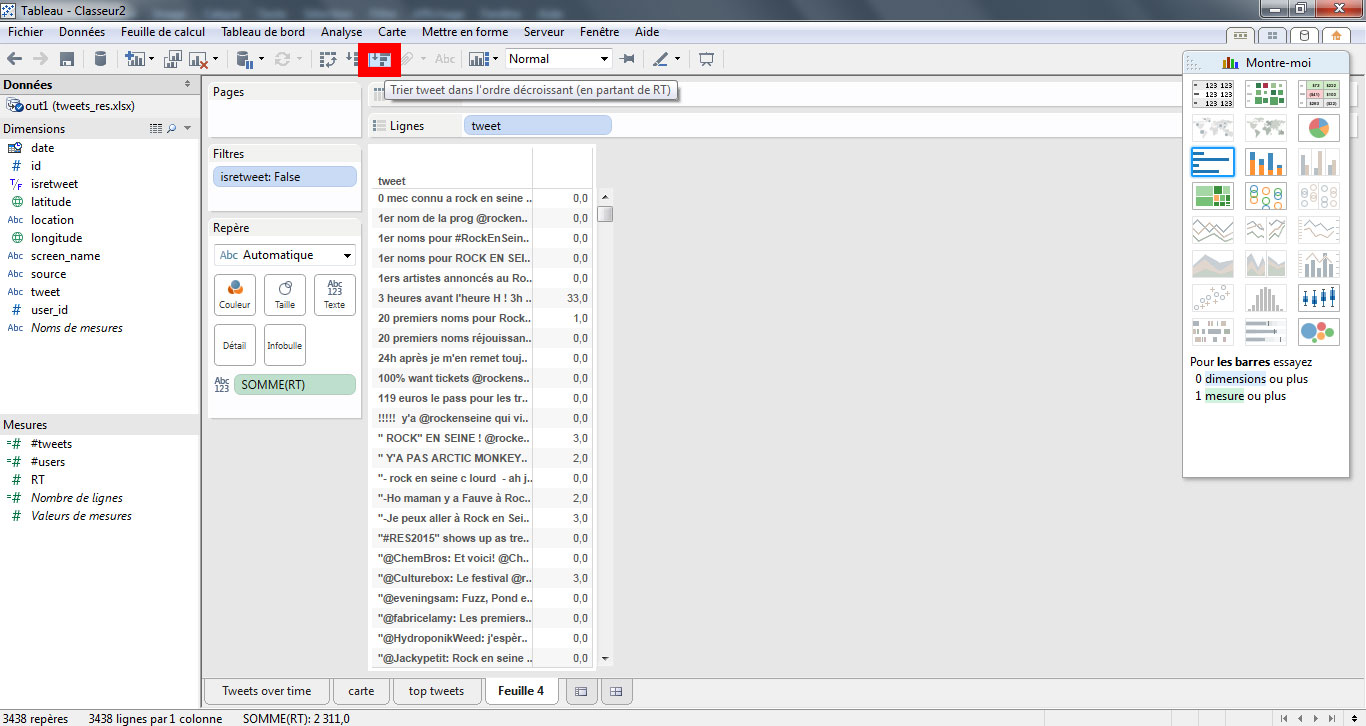
- J’ajoute les champs « screenname » et date en lignes. Le format de date n’est pas bon, donc je sélectionne « Jour ». Cependant, ma visualisation est cassée.
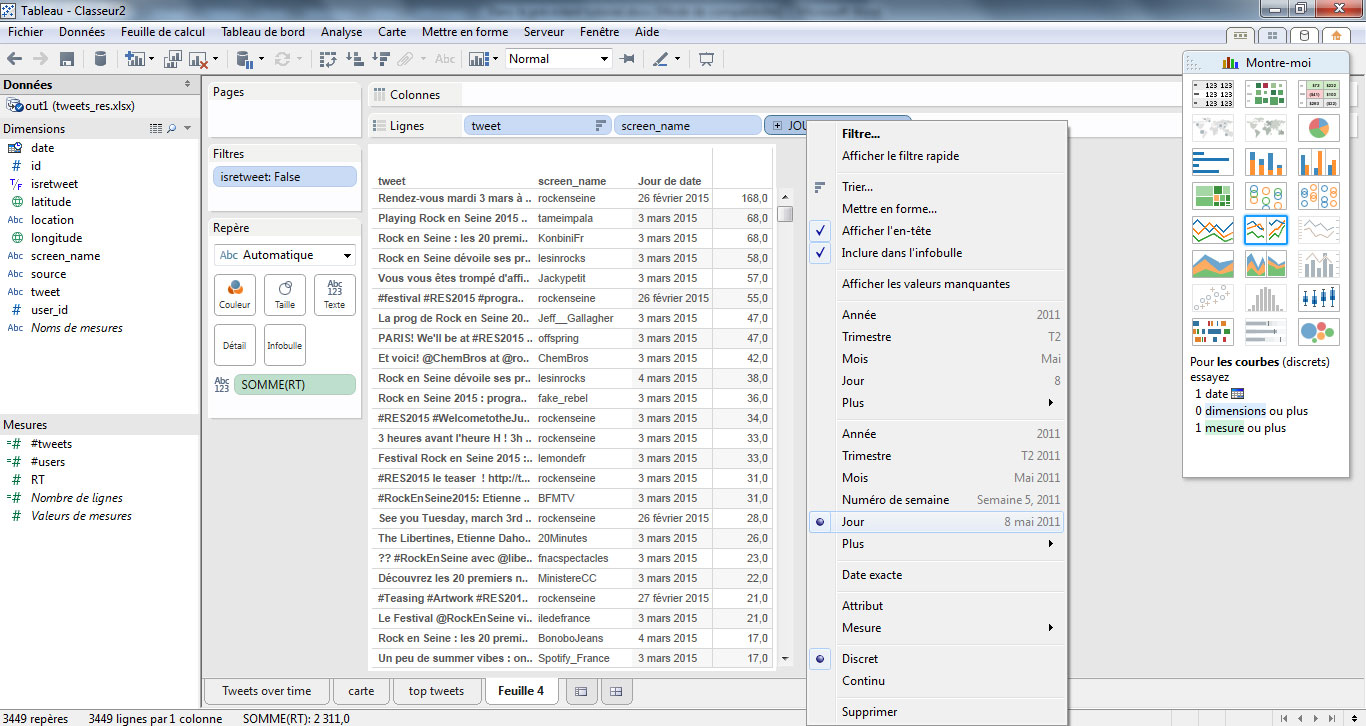
- Je change donc le format de visualisation grâce à ma palette « Montre moi », pour choisir le format tableau.
- Je réorganise mes variables dans le bon ordre, de cette manière :

Analyse : On note que le message qui a reçu le plus d’écho a été publié par le compte officiel du Rock en Seine, quelques jours avant l’annonce de la programmation (28 février). L’annonce faite le 3 mars n’a obtenu que 68RT.
> Le top des auteurs
Il est intéressant de regarder quels sont les utilisateurs qui ont majoritairement pris la parole au cours de cette période. C’est très simple : je duplique mon onglet (bouton droit sur l’onglet) et je supprime les champs « date » et « tweet ». J’obtiens ainsi un tableau des utilisateurs avec la somme de RT obtenus pour chacun d’eux.
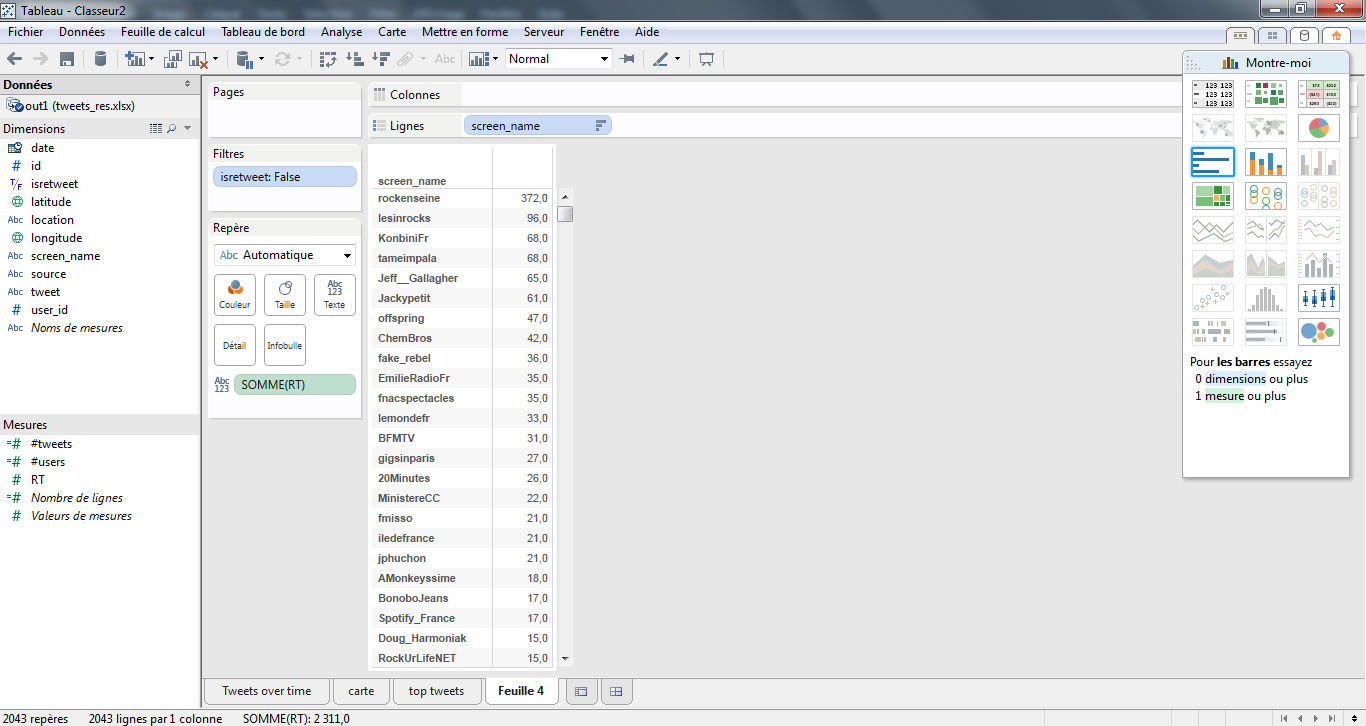
Néanmoins, ce tableau peut amener à des interprétations partiellement erronées. Nous allons donc créer un nouvel indicateur qui correspondra au nombre de RT obtenu en moyenne par un utilisateur. Pour cela, je clique bouton-droit dans ma section « mesure » puis sur « Créer un champ calculé ».
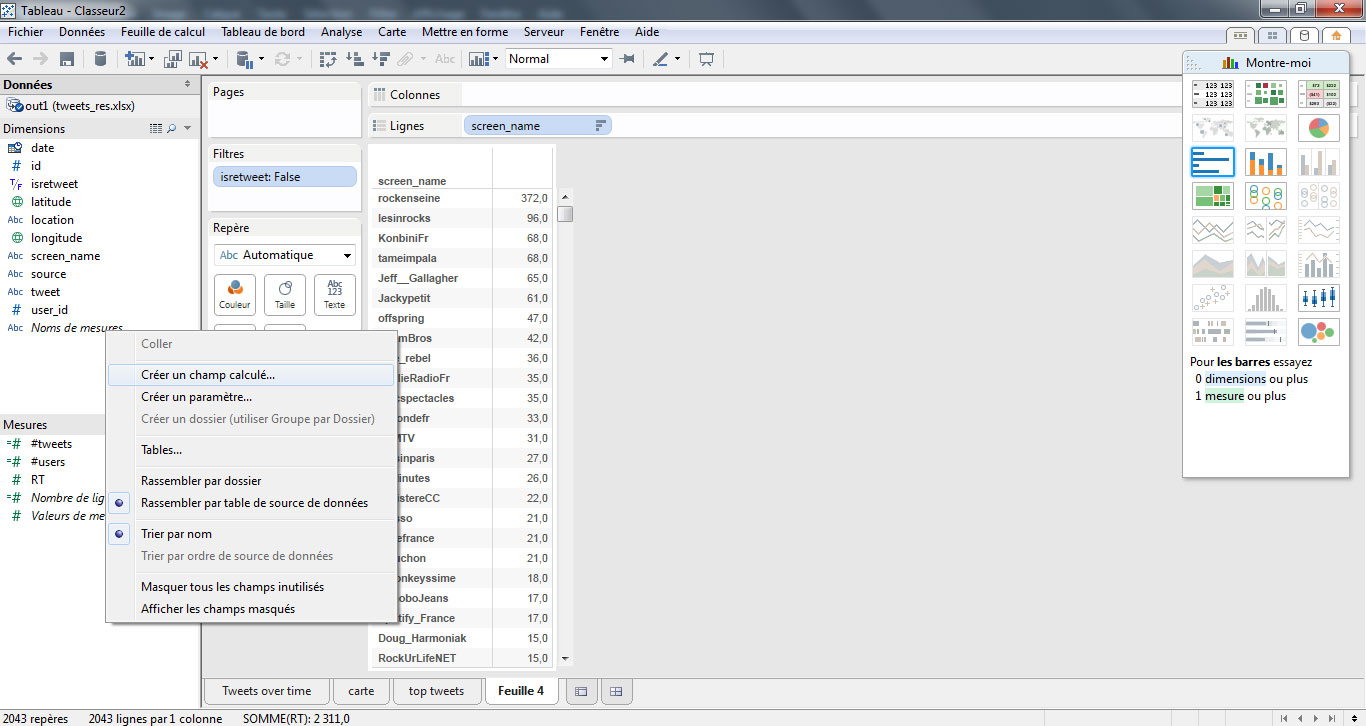
Je donne un nom à ce nouveau champ et je tape la formule suivante : sum([RT])/countd([#tweets])
Cette formule signifie que je divise la somme des RT obtenus par un utilisateur par le nombre de tweets qu’il a émis. J’ajoute ensuite ce champ à mon tableau.
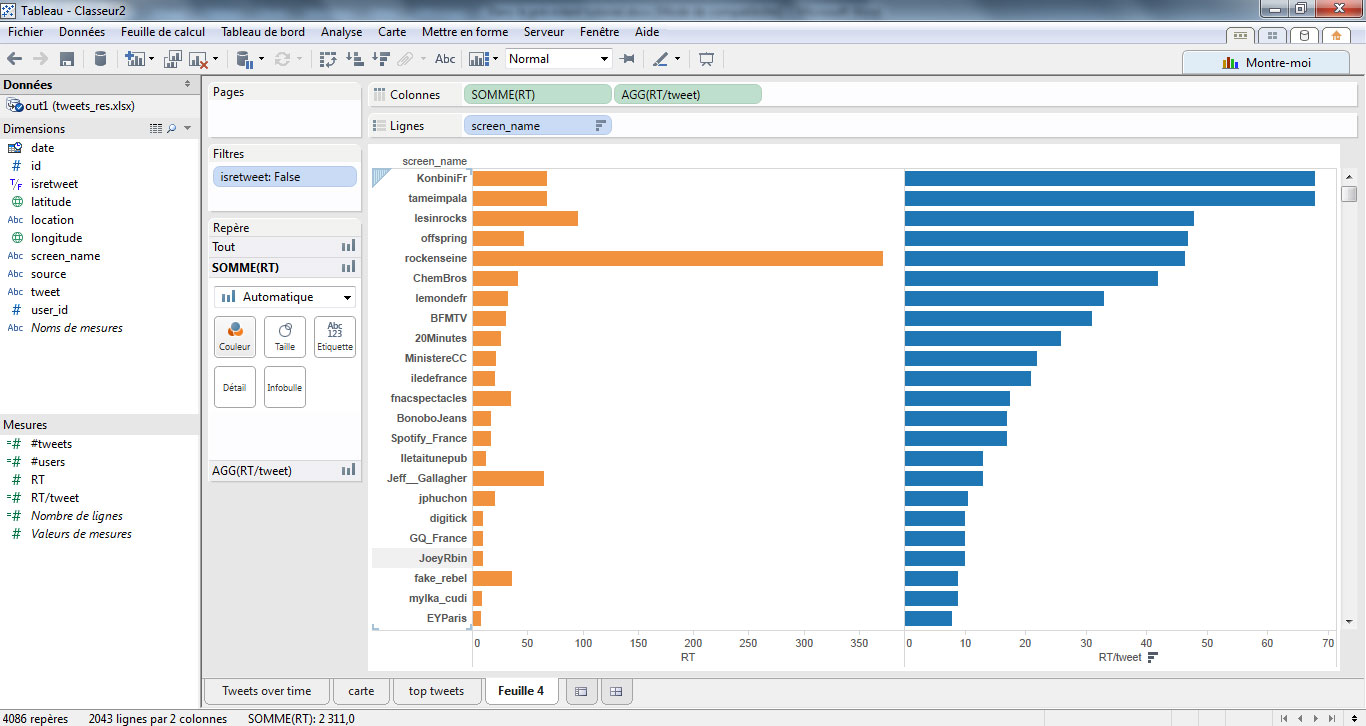
Je peux réordonner le tableau et choisir une visualisation sous forme de barres pour observer les disparités.
En effet, si le compte officiel du Rock en Seine a généré beaucoup de RT au cours de la période analysée, ce sont plutôt les médias (Konbini, Les Inrocks) et les artistes programmés (Tame Impala, Offsprings) qui obtiennent un meilleur ratio.
> Depuis quel terminal les auteurs publient-ils ?
Twitter nous fournit un champ « source » qui indique depuis quel client l’utilisateur a tweeté. Je vais réaliser un nouveau tableau, classé par nombre d’utilisateurs. J’ajoute simplement une condition de filtrage, très pratique fournie par Tableau, permettant de n’afficher que les x premiers résultats.
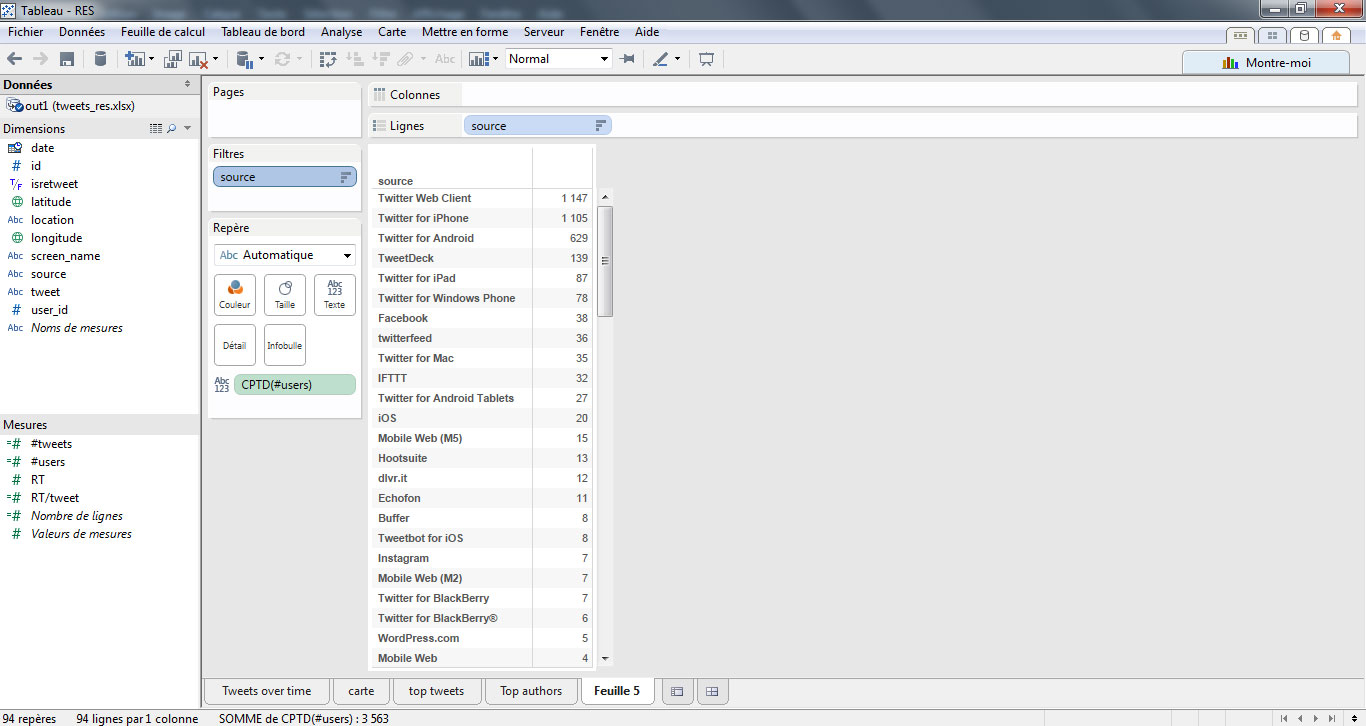
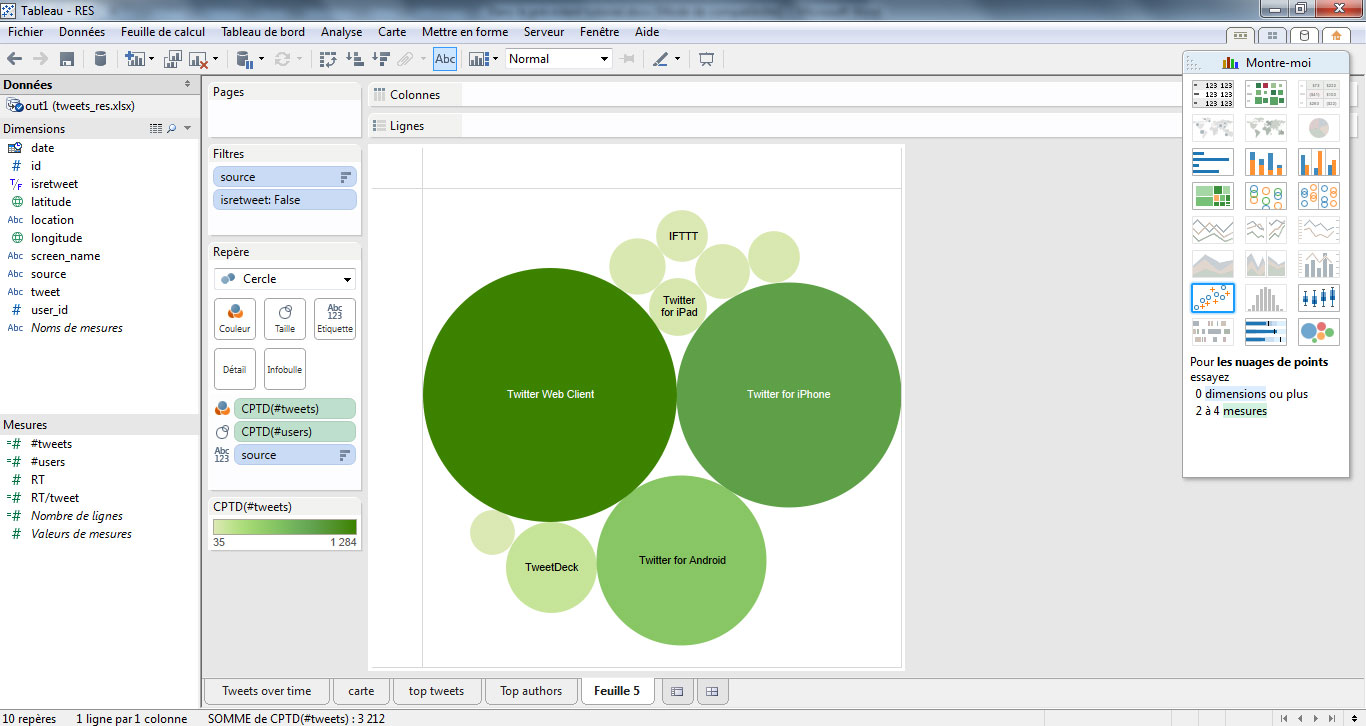
On peut donner un côté plus esthétique à ce tableau en plaçant les champs source, #users et #tweets respectivement sur étiquette, taille et couleur. Voici le graphique obtenu.
> Produire un nuage de mots-clés avec les hashtags et les mentions
Nous avons entreposé les données dans d’autres fichiers. Je clique sur Données > Se connecter aux données et je recommence la procédure déjà expliquée en début d’article.
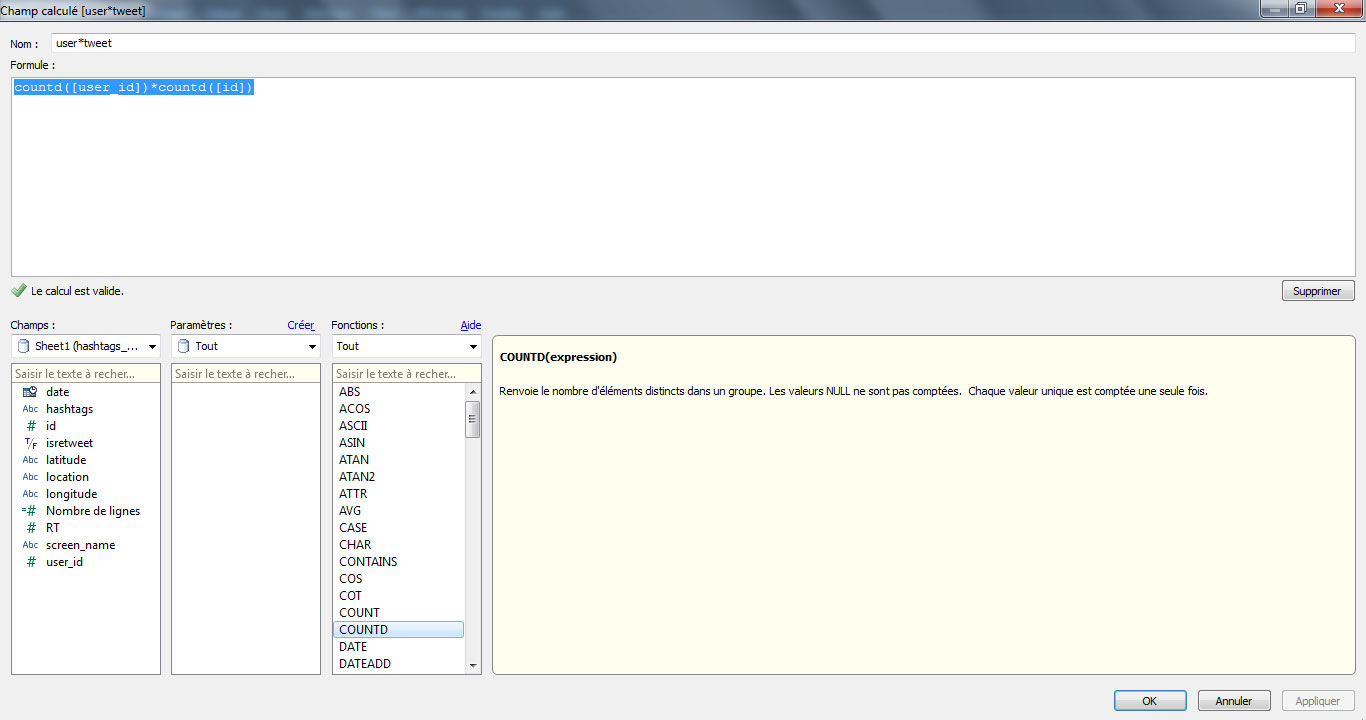
Les variables à ma disposition pour réaliser le nuage de mots-clés sont assez limitées. Je pourrais choisir d’attribuer une taille et une couleur à chaque mot en fonction du nombre de tweets qui contiennent le hashtags, le nombre d’utilisateurs qui l’ont mentionné et le nombre de RT engendré par les messages contenant le hashtags. Je vais créer un champs calculé qui multiplie le nombre de tweets avec le nombre d’utilisateurs mentionnant un hashtag de manière à obtenir un score d’usage. En effet, un hashtag pourrait avoir été mentionné de nombreuses fois par un petit nombre d’utilisateurs et viendrait fausser la visualisation. Je crée un champs calculé avec la formule countd([user_id])*countd([id])
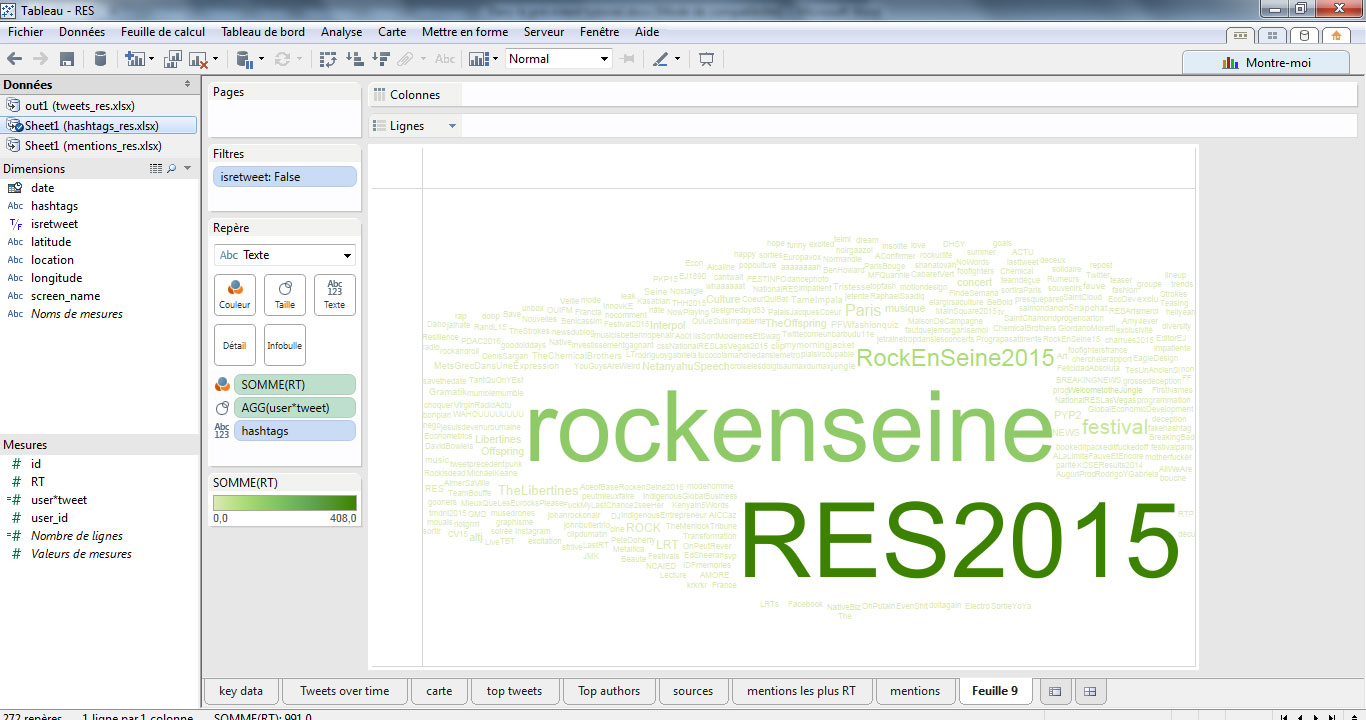
Je place ensuite mes champs :
- je filtre les RT avec « isretweet »
- je place hashtags sur « texte »
- j’attribue mon champ calculé user*tweet sur Taille
- et RT sur couleur
- je m’assure que la visualisation est bien au format texte dans ma palette.
A ce stade, la visualisation n’est pas très explicite car les hashtags #Rockenseine, #RES2015, #rockenseine2015 sont surreprésentés, trop d’items apparaissent à l’écran et l’échelle des couleurs n’est pas ajuster. Nous allons commencer par ajuster cette échelle en utilisant 3 niveaux de couleurs.
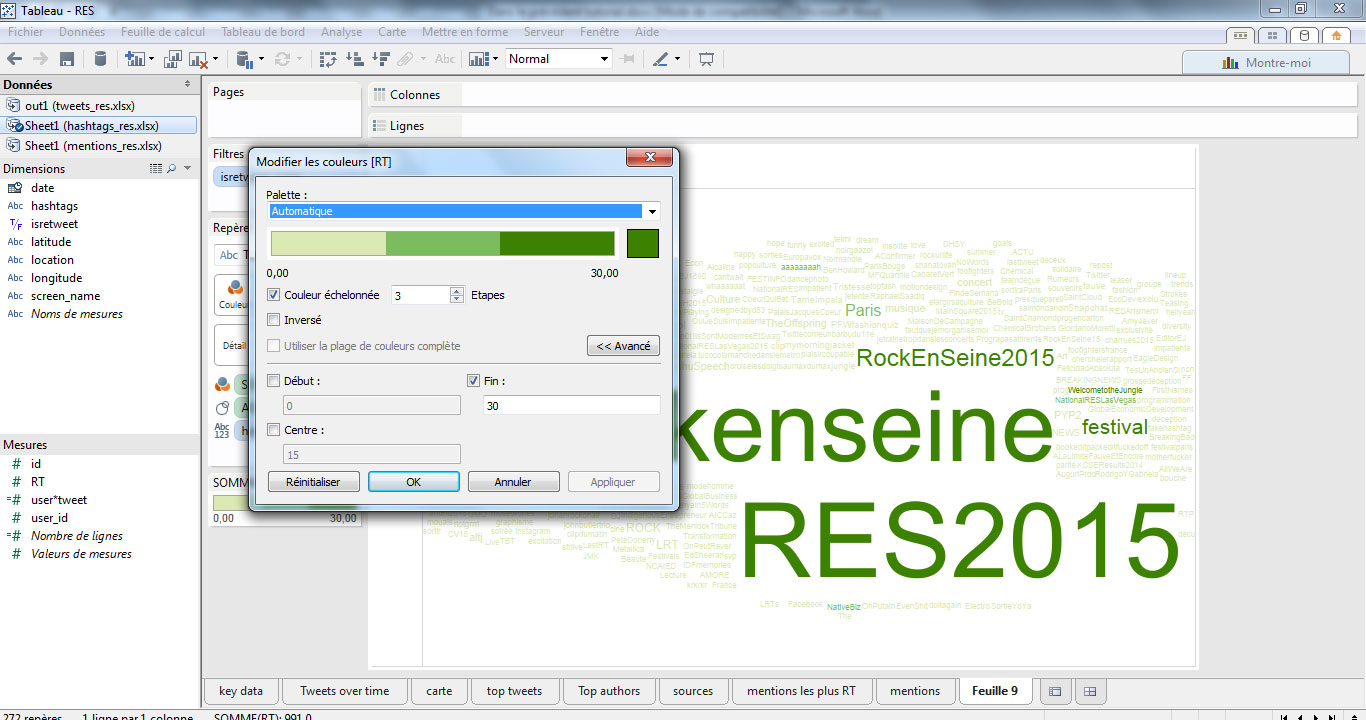
Puis, nous filtrons sur les 100 premiers hashtags en fonction de notre champ calculé.
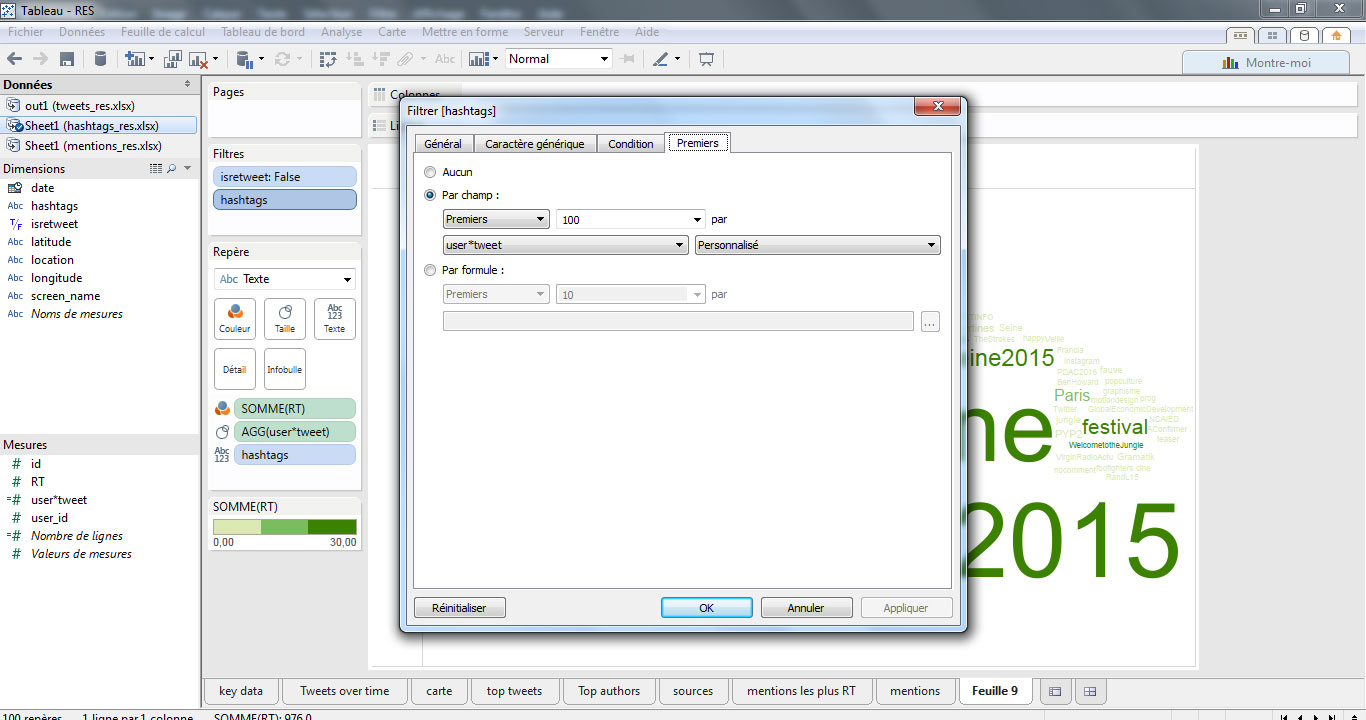
Ensuite, nous allons exclure de l’analyse les 4 hashtags surreprésentés en les sélectionnant, puis en cliquant sur le bouton-droit>Exclure.
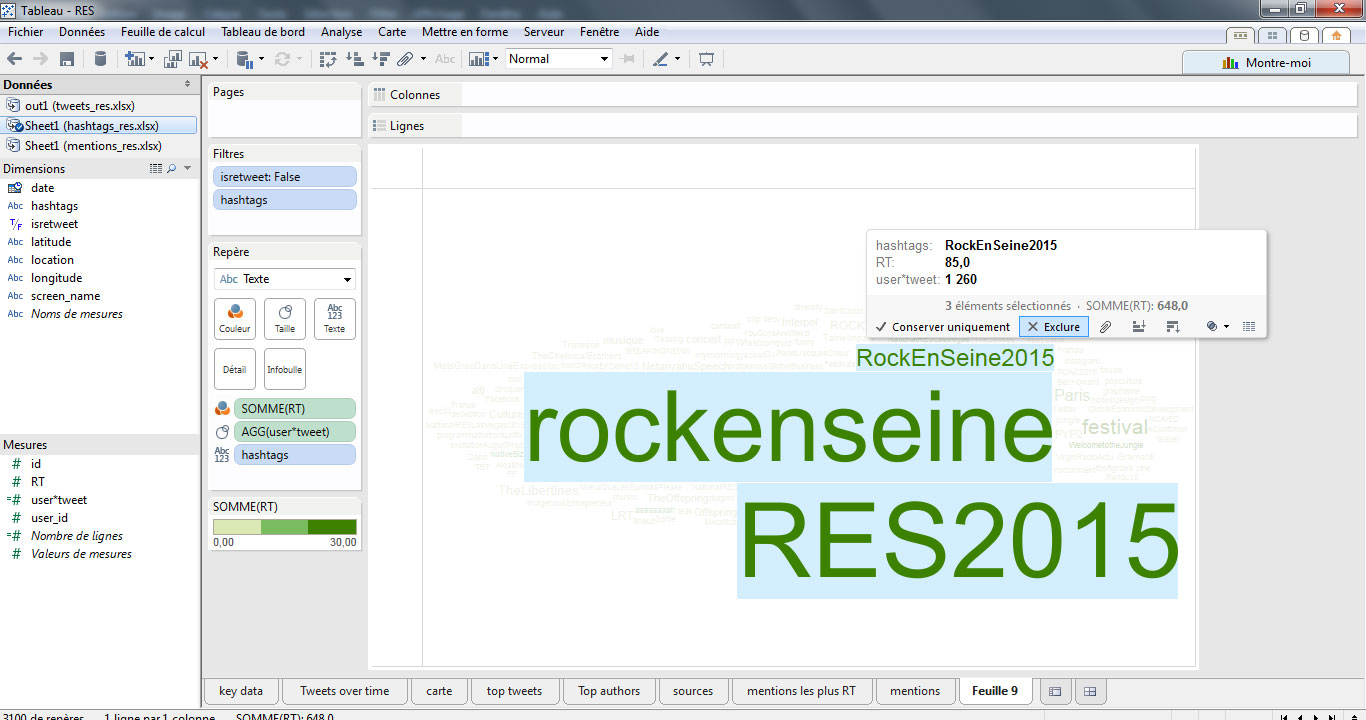
Je réajuste mon échelle de couleur et j’ajoute un filtre de date pour me concentrer sur l’annonce du festival. On obtient à ce stade un nuage de mots-clés beaucoup plus intéressant, qui révèle notamment les groupes de la programmation les plus attendus : The libertines, Tame Impala, Interpol…
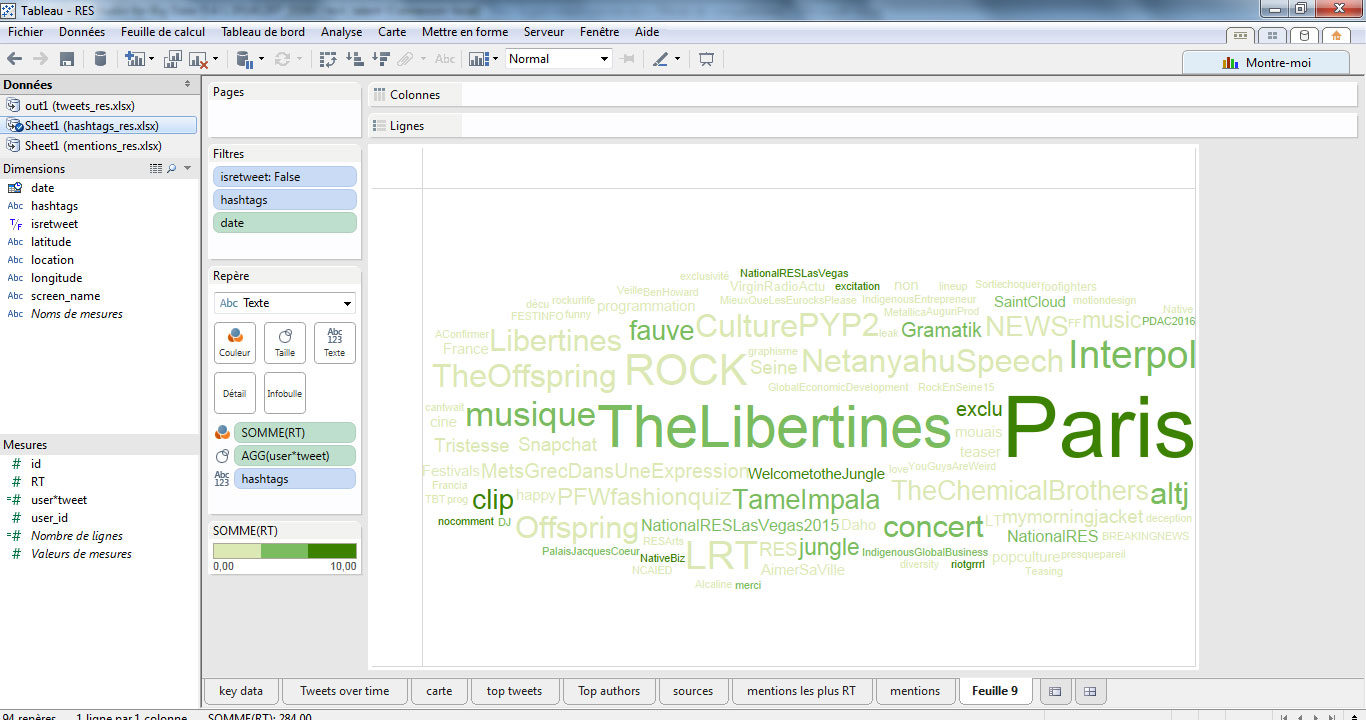
Enfin, si l’on veut être pointilleux (et si la liste des hashtags n’est pas trop longue), on peut créer des groupes de hashtags. Par exemple, nous pouvons regrouper les hashtags #libertines et #thelibertines.
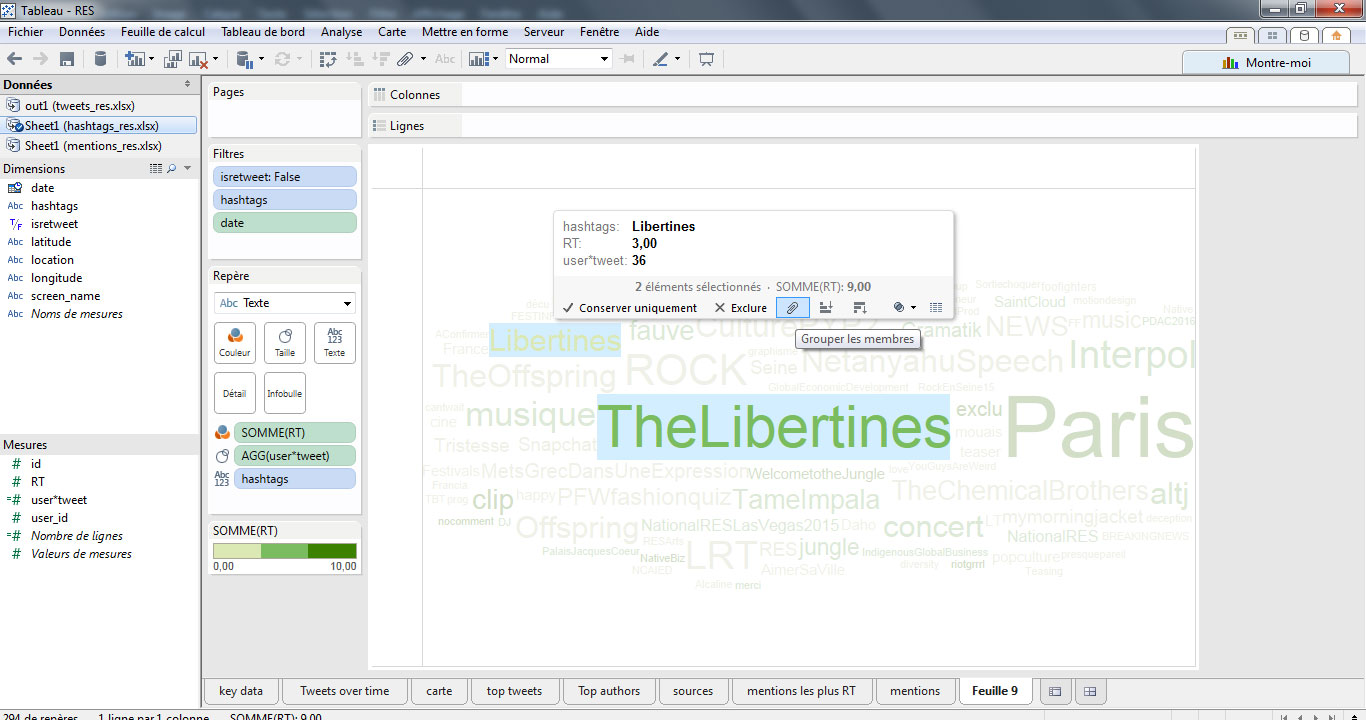
On peut réaliser une visualisation similaire avec les mentions, ou choisir un format de cercle. Ce graphe est particulièrement riche en information puisque l’on identifie la suractivité du responsable de la programmation (@fmisso) en volume de tweets et l’influence des groupes en nombre de RT.
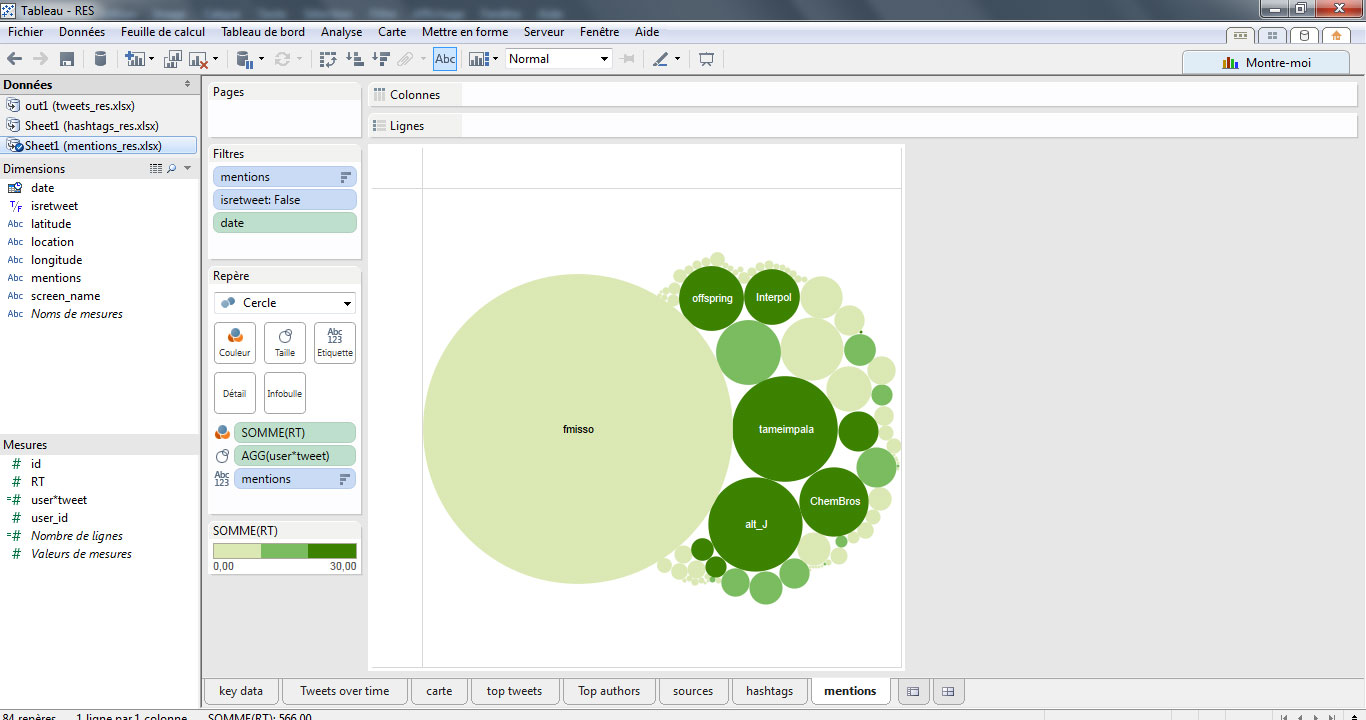
> Quels sont les utilisateurs mentionnés par le compte officiel @rockenseine
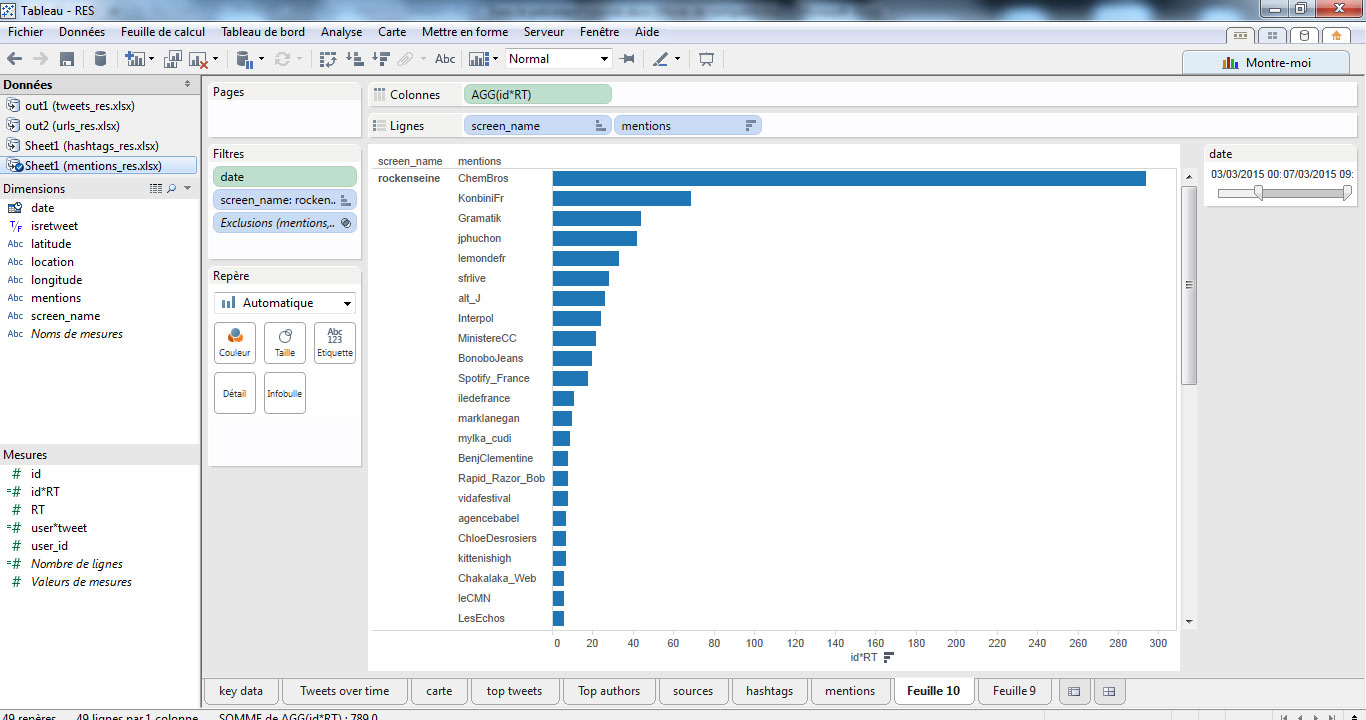
On peut s’intéresser à l’activité du compte officiel @rockenseine pour identifier les sujets qui ont retenu le plus l’attention de ses lecteurs, par l’analyse des mentions. Pour cela, nous allons commencer par placer un filtre à l’aide du champ « screenname » qui ne retiendra que le compte @rockenseine :
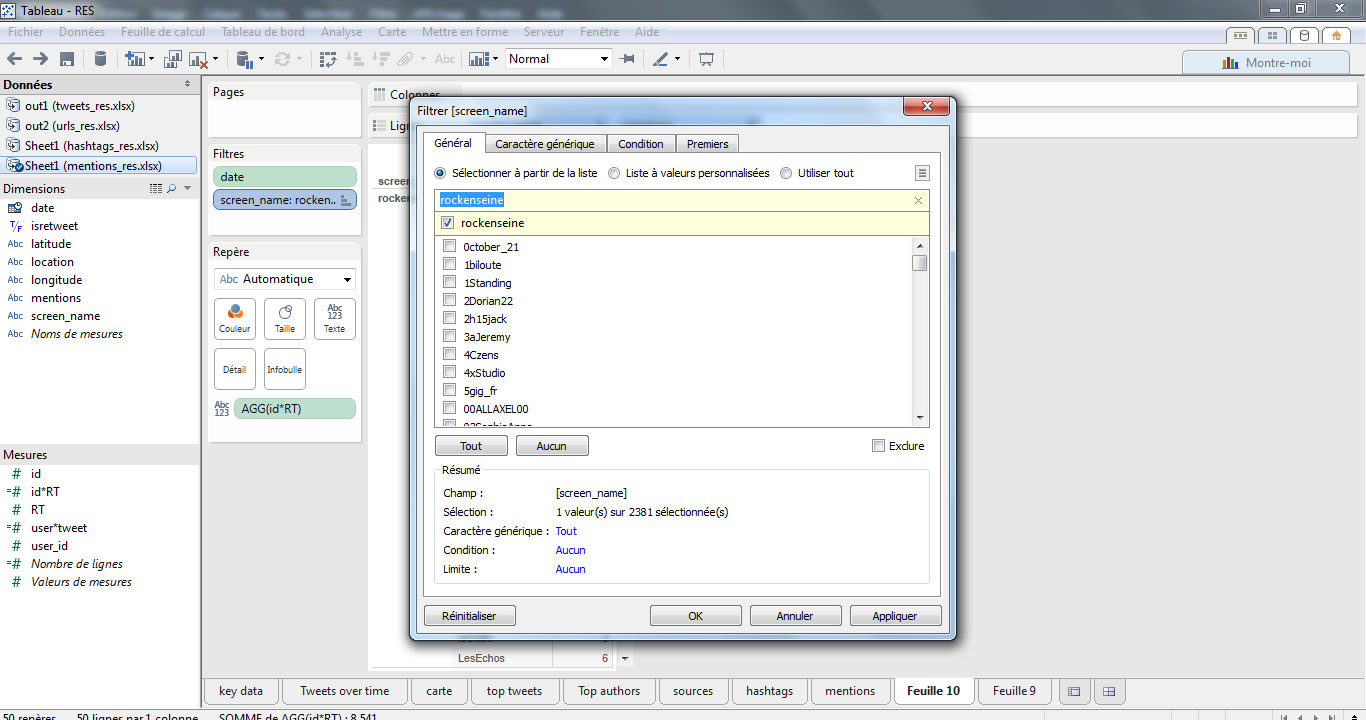
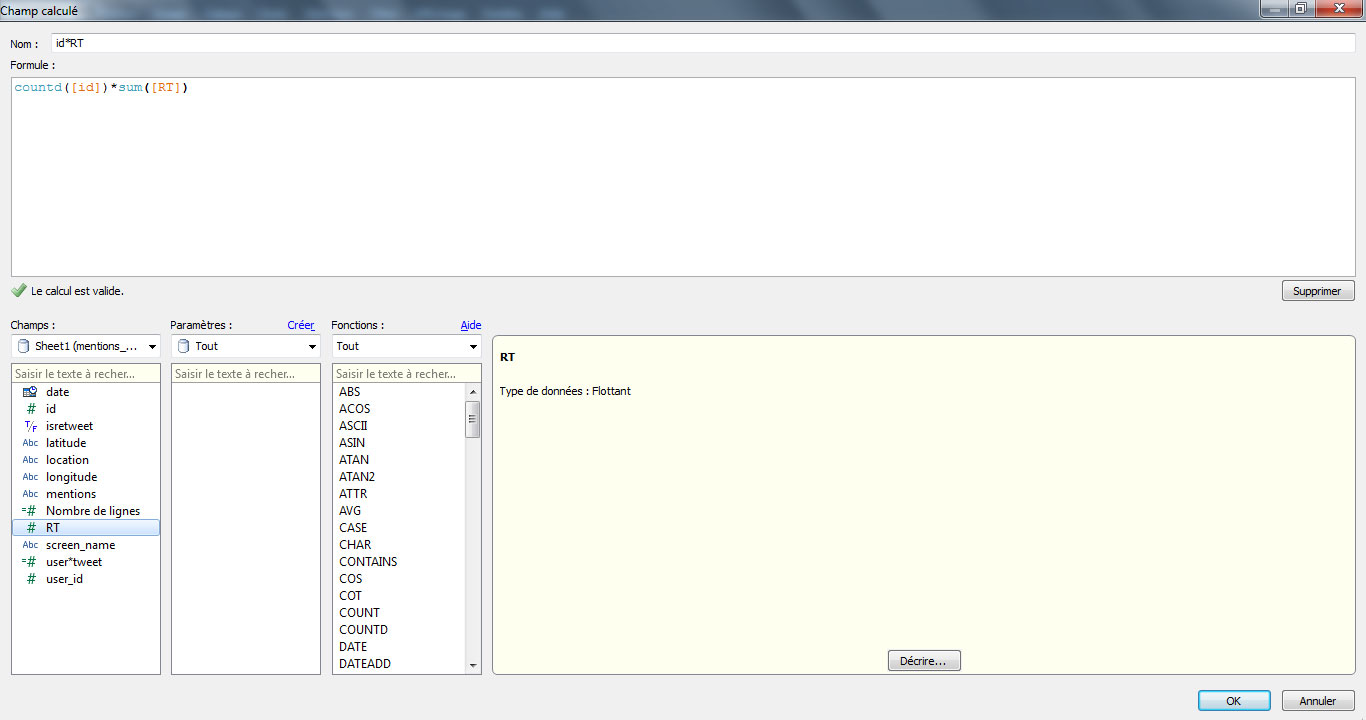
Puis, nous plaçons le champ « mentions » afin de visualiser l’ensemble de la liste des utilisateurs mentionnés par le compte @rockenseine. Il nous intéresse de savoir combien de tweets contiennent chaque mention, et combien de RT ces tweets ont engendré. Plutôt que d’utiliser deux indicateurs, nous allons créer un champ calculé avec la formule countd([id])*sum([RT])
Je place mon champ, je modifie la visualisation pour avoir un diagramme barre, j’exclue la mention @rockenseine, je filtre sur la date et j’obtiens ce beau graphique :
> le top des URLs partagées
Un fois connecté à mon fichier contenant les URLs, je peux réaliser une analyse très simple en produisant un top 20 des URLS afin de mesurer l’impact des retombées presse. Pour cela, j’utilise un champ calculé countd([user_id])*countd([id]). Nous avons déjà expliqué comment produire ce genre de visualisations, dont voici le résultat :
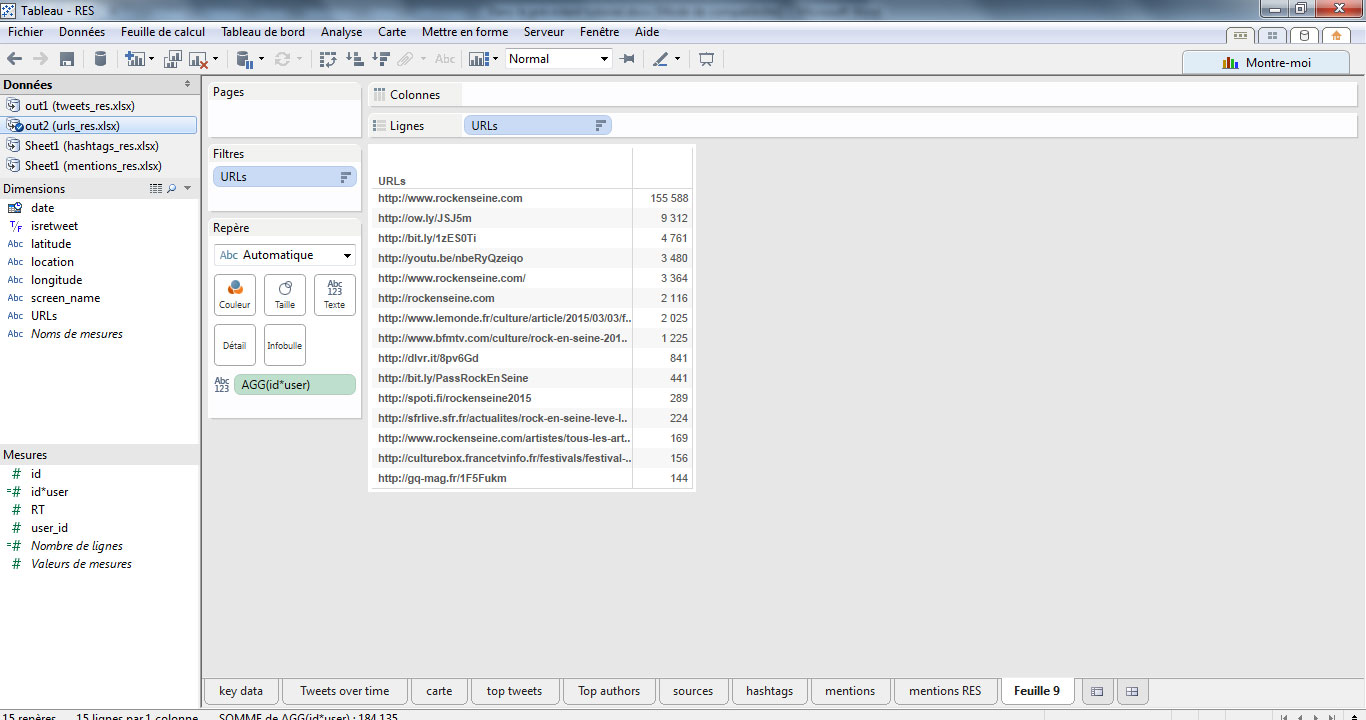
Si l’on exclue les supports officiels du festival, on identifie la performance des médias et partenaires au moment de l’annonce : les Inrocks, Konbini, leMonde.fr, BFM, 20minutes, Spotify, SFR Live, …
> Quels mots sont les plus utilisés ?
En analyse bonus, j’ai découpé tous mes tweets en mots à l’aide de Talend afin de produire une analyse de fréquence. On pourrait appliquer une méthode plus fine à l’aide de l’outil Iramuteq (voir la méthode : « Comment articuler analyse des réseaux et des discours sur Twitter » de Nikos Smyrnaios et Pierre Ratinaud), néanmoins je vous propose quelque chose de simple à mettre en œuvre avec Talend.
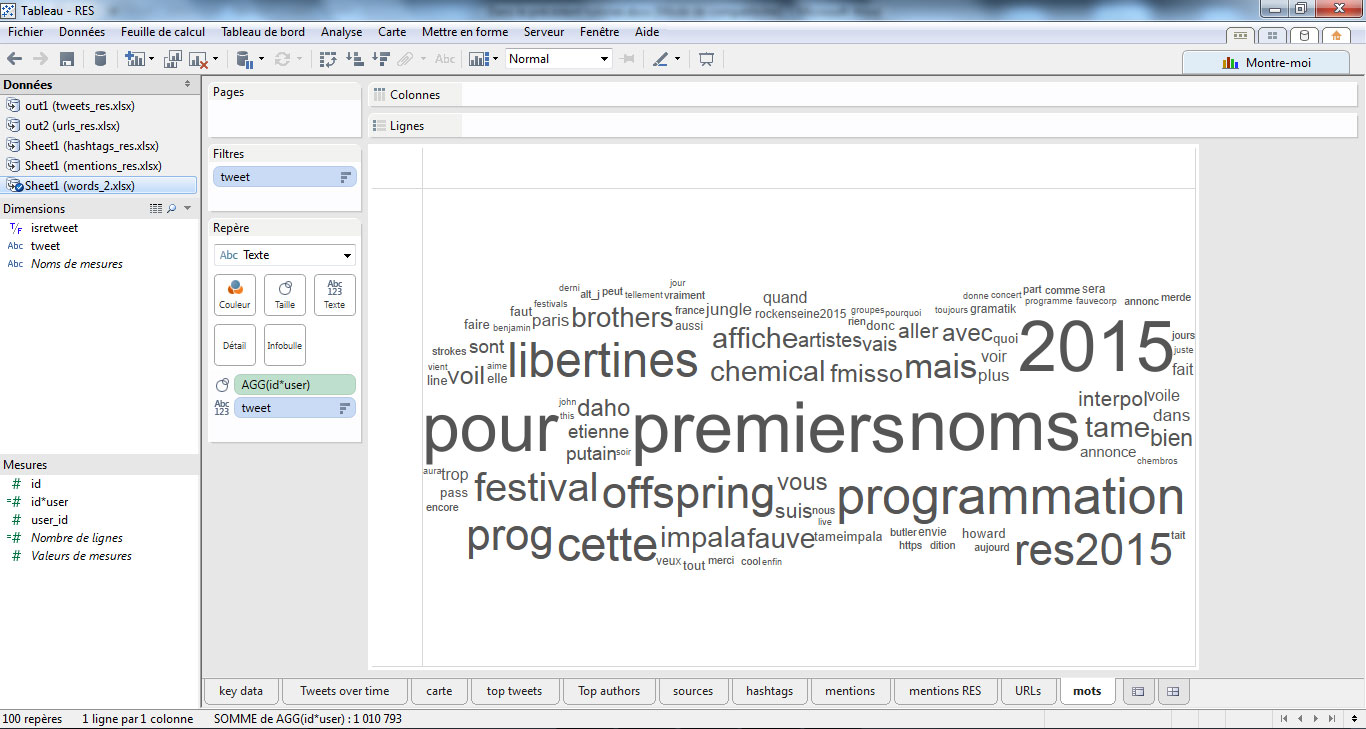
En reprenant, la méthode explicitée pour la création d’un nuage de mot-clés, on arrive à cette visualisation qui présente des variations par rapport à l’analyse de hashtags. On identifie notamment des opinions tranchées (« merde », « cool », « putain », etc. )
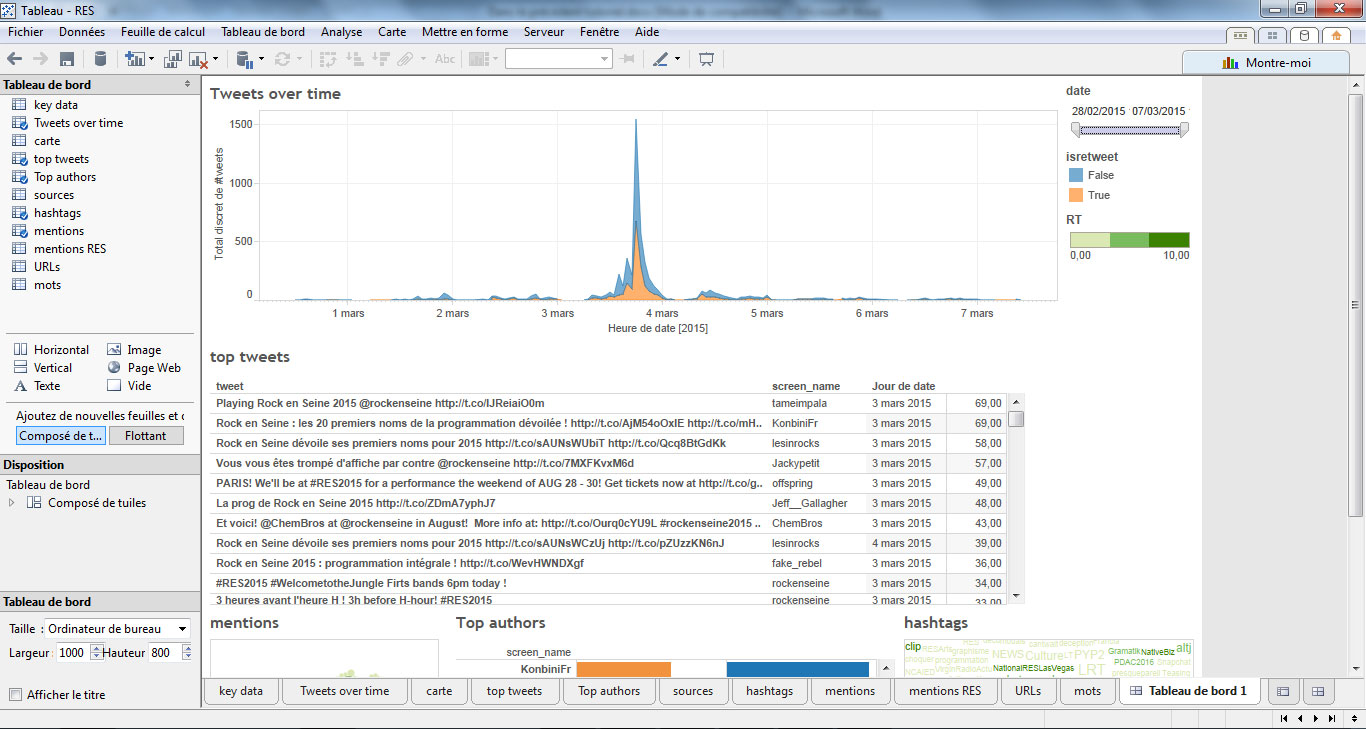
Pour terminer, Tableau Desktop vous permet de constituer un tableau de bord en alliant l’ensemble des visualisations produites.
Une réponse sur « Tutoriel – Analyser un dataset de tweets avec Tableau Desktop »
[…] vous de jouer !!! Après cela, il ne reste plus qu’à analyser les données […]