Ce tutoriel s’adresse à des dataminers ou data scientists qui sont confrontés à une problématique de text mining usuelle : comment identifier la langue d’un message. Ce tutoriel présente une implémentation simple de la librairie Java ‘language-detection‘ au sein de Talend. Le tutoriel se veut le plus pédagogue possible pour les profanes de Talend, et ne connaissant pas forcément la programmation Java.
La librairie ‘language-detection’ permet d’identifier de manière fiable des messages plutôt longs et bien orthographiés dans plus de 53 langues. Le traitement ci-dessous m’a permis d’optimiser mes analyses lexicométriques en segmentant un corpus hétérogène de commentaires Facebook mêlant plusieurs langues. En filtrant à partir de la langue détectée par cette librairie, je pouvais appliquer des traitements spécifiques aux messages en français, en anglais, etc.
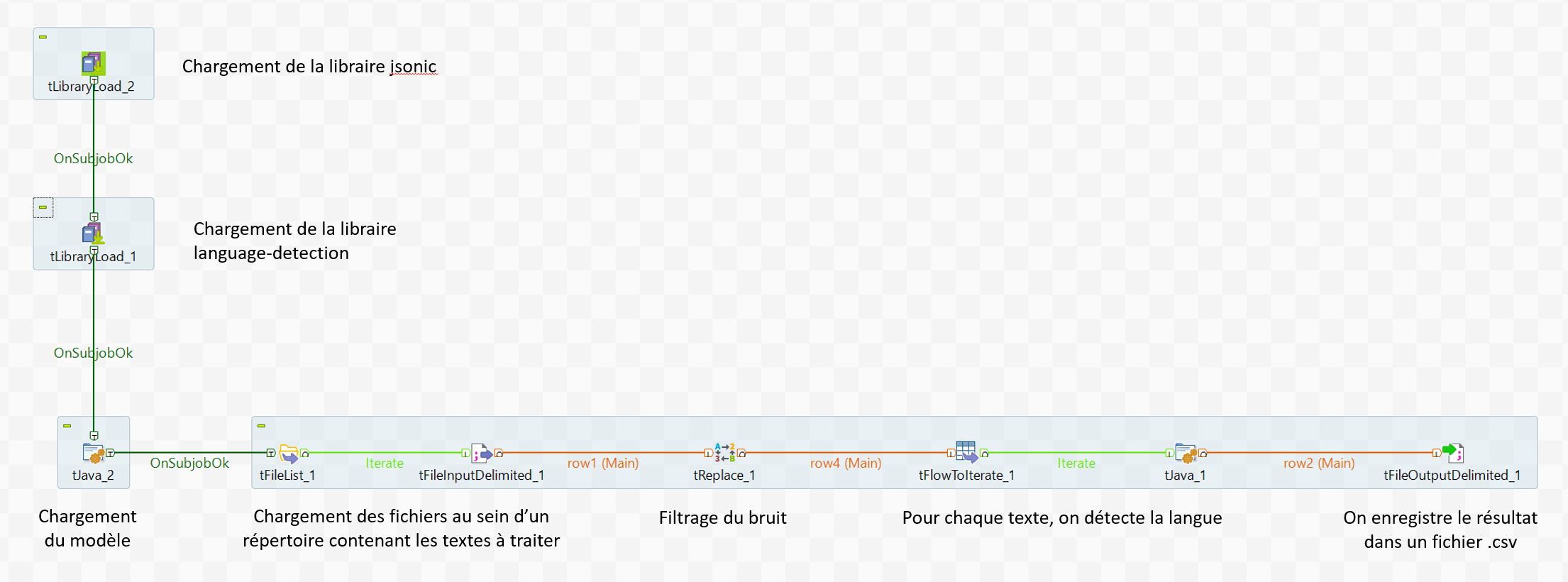
Le processus général de traitement est le suivant :
1. On charge les librairies Java requises dans Talend
2. On charge le modèle prédictif souhaité
3. On charge les fichiers contenant les textes pour lesquels la langue doit être identifiée
4. On filtre le bruit des messages qui pourrait biaiser la détection de la langue
5. On appelle la librairie pour détecter la langue et obtenir un score de probabilité
6. On enregistre les résultats dans un fichier
http://desterritoiresauxgrandesecoles.org/?kantorapiwet=rencontre-cognac&fb2=b0 Pré-requis :
Une fois la librairie téléchargée sur Git Hub, décompressez le fichier .zip dans un répertoire de votre choix (ex : C:/MesDocuments/language-detection-master). La librairie propose deux modèles de détection, associés aux répertoires :
– ‘profiles’, modèle entraîné à partir des résumés de la base d’articles Wikipedia pour chaque langue
– ‘profiles.sm’, modèle entraîné à partir de tweets (censé optimiser la détection sur des messages courts)
Etape n°1 – Configurer les variables de contexte du job Talend
Nous créons un nouveau job intitulé ‘language_detection’. Dans ce tutoriel simplifié, nous avons besoin de 2 variables de contexte :
- une variable ‘input’ précisant le dossier où se trouvent nos fichiers avec les textes à traiter. Par exemple C:/MesDocuments/Talend_inputs
- une variable ‘profileDirectory’ spécifiant le modèle prédictif à appliquer, c’est à dire pointant vers le répertoire C:/MesDocuments/language-detection-master/profiles ou C:/MesDocuments/language-detection-master/profiles.sm

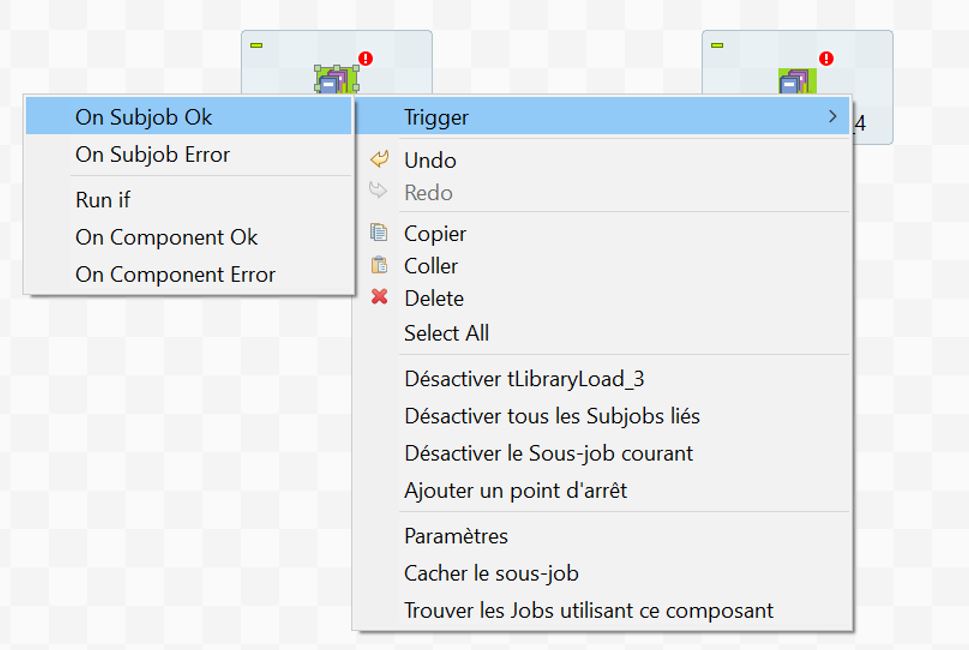
Kokomo Etape n°2 – Chargement des librairies
Nous insérons deux composants tLibraryLoad reliés par une commande OnSubjobOk. Pour cela, tapez le nom du composant sur l’espace de travail et sélectionnez-le. Puis, cliquez bouton droit > ‘Trigger’ > ‘OnSubjobOk’. Pointez votre souris pour lier les deux composants. Le lien OnSubjobOk signifie que si le chargement de la première librairie est valide, alors on passe au chargement de la seconde.
Dans les paramètres de ces composants, sélectionnez les fichiers jsonic-1.2.0.jar (ou une version plus récente) et langdetect.jar que vous avez téléchargés (contenu dans le dossier C:/MesDocuments/language-detection-master/lib).
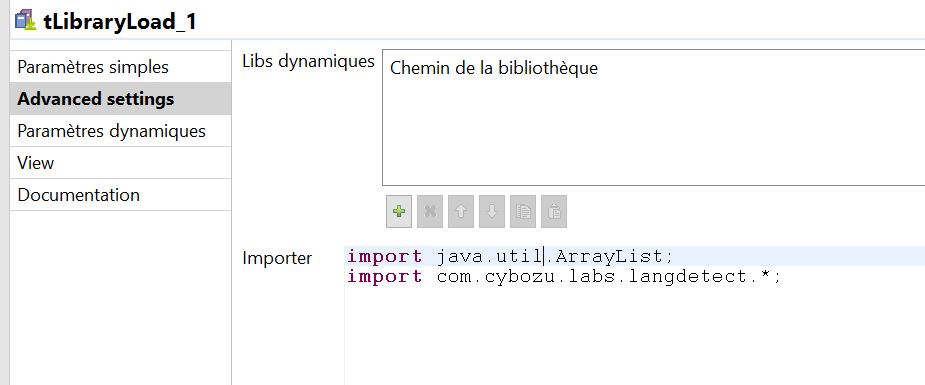
Dans les paramètres avancés du composant tLibraryLoad pour lequel vous avez chargé la librairie langdetect.jar, précisez que vous importez l’ensemble des fonctions :
import java.util.ArrayList; import com.cybozu.labs.langdetect.*;
cormeilles en parisis rencontre musulmane Etape n°3 : Sélection et chargement du modèle
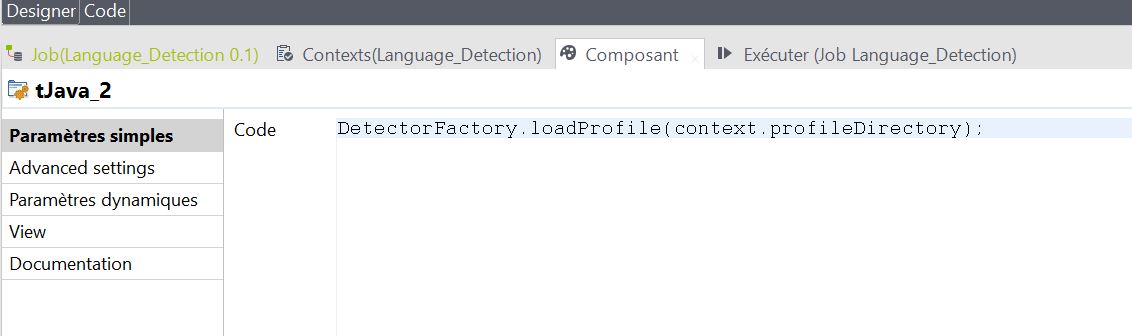
Insérez un composant tJava permettant d’exécuter un script Java. Liez le précédent tLibraryLoad à ce composant avec un lien OnSubjobOk, c’est à dire que lorsque le chargement des deux librairies contenant les fonctions que nous souhaitons utiliser sont valides, alors on exécute un script Java.
Le script consiste en l’appel d’une seule fonction :
DetectorFactory.loadProfile(context.profileDirectory);
Explication : au sein d’une instance DetectorFactory, on charge un profil qui se situe dans un répertoire. Nous avons configuré ce répertoire à l’étape n°1 et nous appelons la variable de contexte ‘profileDirectory’. Sur Talend, une variable de contexte est préfixée de ‘context.’. Vous pouvez visualisez les variables disponibles à l’aide du raccourci CTRL+Espace.
Etape n°4 : Chargement des textes
Nos données sont contenues dans plusieurs fichiers .csv, qui sont sauvegardés dans un répertoire. Chaque fichier possède la même structure, à savoir deux colonnes : un ID et le message.

Insérez un composant tFileList lié au reste par un lien OnSubjobOk. Ce composant parcoure un répertoire et charge successivement des fichiers selon un filtre. On paramètre le composant en sélectionnant le répertoire à l’aide de la variable de contexte ‘input’. Le masque du nom de fichier correspond à l’extension *.csv
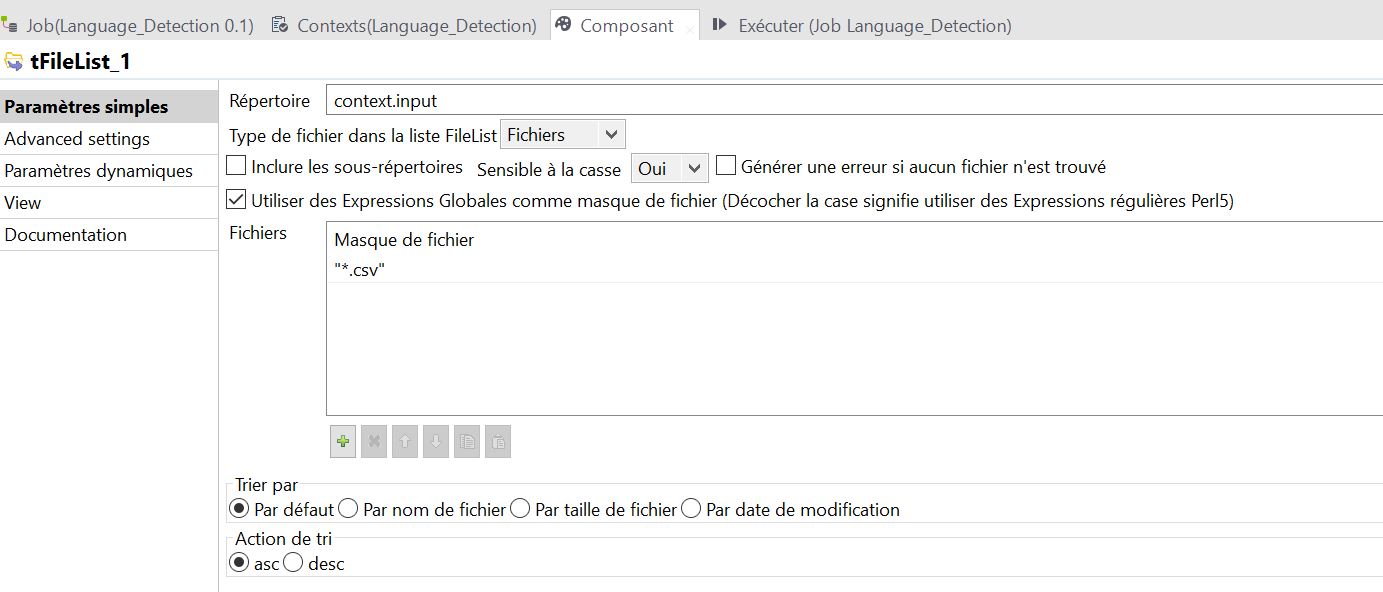
Insérez un composant tFileInputFileDelimited et tirez un lien ‘iterate’ depuis le composant tFileList précédent. Ce composant permet de lire un fichier délimité (.csv). Le lien iterate signifie qu’à chaque fois que le composant tFileList va identifier un fichier correspondant au paramétrage (c.a.d un fichier csv), alors il va le transmettre au composant tFileInputDelimited qui lira son contenu.
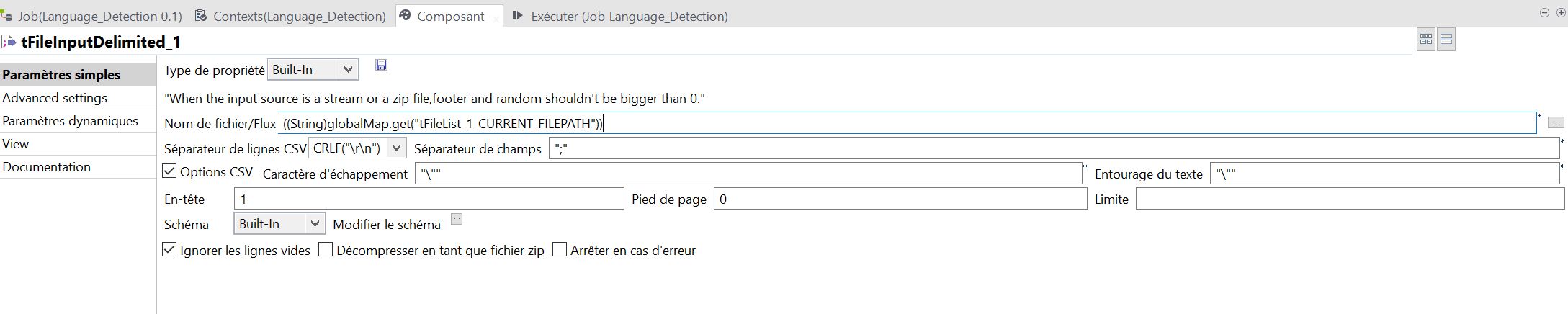
Etant donné que la localisation du fichier à lire va changer à chaque itération, on appelle une variable issue de tFileList contenant le chemin d’accès du fichier de l’actuelle itération. Pour cela, dans les paramètres tapez CTRL+Espace et sélectionnez la variable tFileList – Current Filepath. Ce qui devrait se matérialiser par le paramètre : ((String)globalMap.get(« tFileList_1_CURRENT_FILEPATH »))
Paramétrez les options du fichier csv, c’est-à-dire :
– le délimiteur (généralement la virgule ou le point-virgule)
– les caractères d’échappement ou l’entourage du texte (« \ » » s’il s’agit de doubles quotes)
– l’encodage des caractères, dans les paramètres avancés (UTF-8)
– la présence d’un en-tête
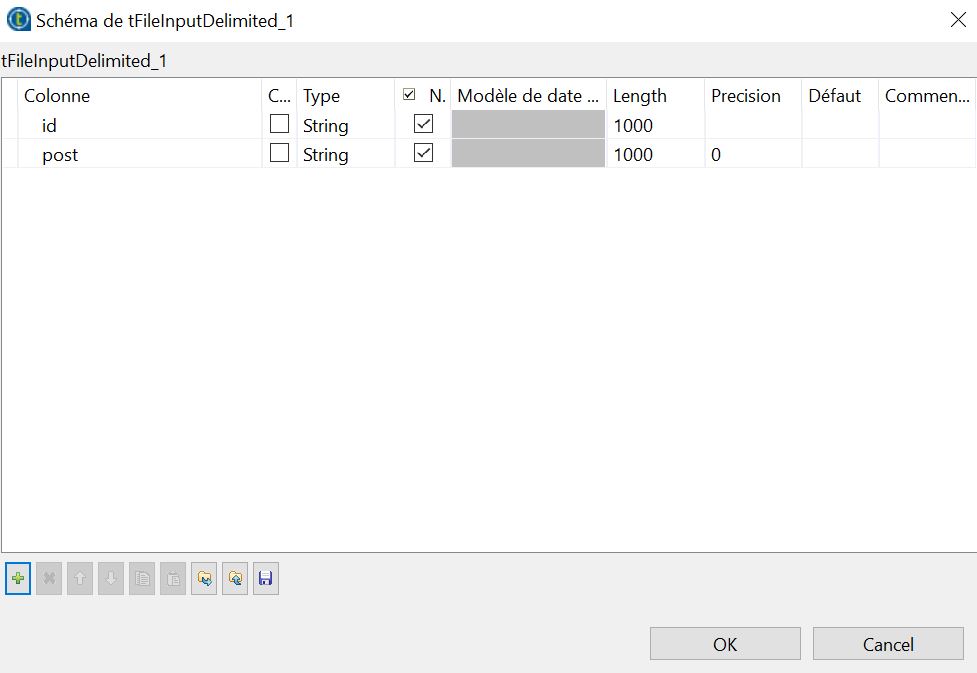
Cliquez-sur « Modifier le schéma » pour préciser le contenu du fichier. Dans notre exemple, nous déclarons 2 variables de type ‘string’ (=texte) correspondant aux colonnes de notre fichier.
Etape n°5 – Filtrer le bruit des messages
Il s’agit d’une étape cruciale pour optimiser la détection de la langue. Certains messages peuvent contenir des syntagmes ou des suites de caractères inappropriés, basiquement des fautes d’orthographes, mais aussi des URLs des chiffres, etc.
Le composant tReplace est utile pour effectuer des substitutions, notamment à l’aide d’expressions régulières. Liez tFileInputDelimeted à ce composant par un lien « main », c’est-à-dire que vous envoyez tout le contenu du fichier vers tReplace.
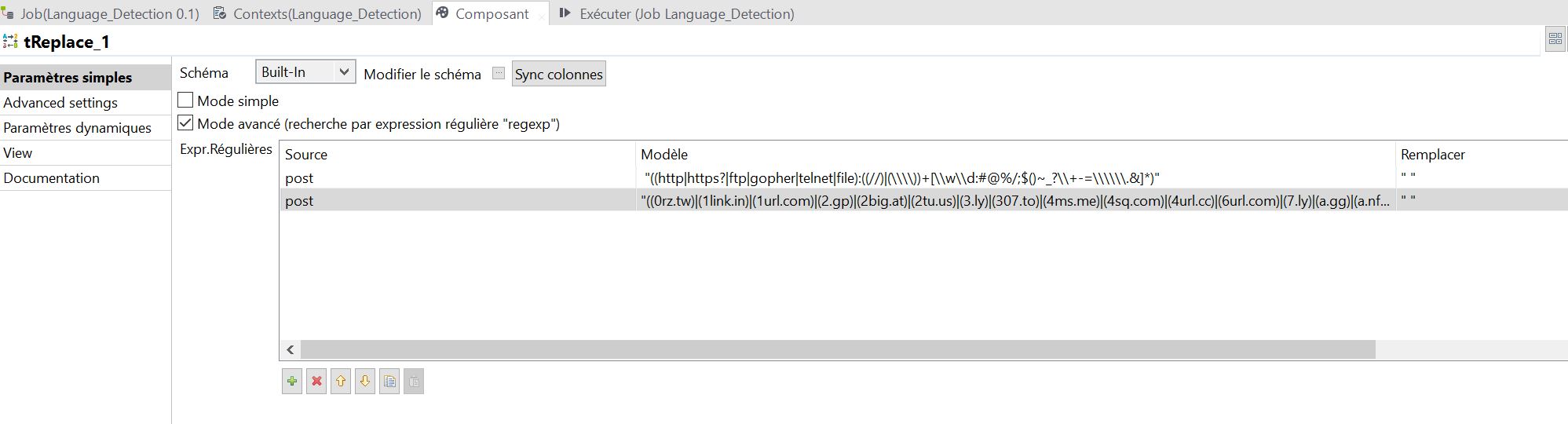
Je partage avec vous deux expressions régulières qui me sont très utiles pour supprimer les URLs contenues dans les messages :
- cette première expression capture la plupart des liens préfixés de http, https, ftp, etc.
"((http|https?|ftp|gopher|telnet|file):((//)|(\\\\))+[\\w\\d:#@%/;$()~_?\\+-=\\\\\\.&]*)"
- cette deuxième expression capture les URLs issues de raccourcisseurs
"((0rz.tw)|(1link.in)|(1url.com)|(2.gp)|(2big.at)|(2tu.us)|(3.ly)|(307.to)|(4ms.me)|(4sq.com)|(4url.cc)|(6url.com)|(7.ly)|(a.gg)|(a.nf)|(aa.cx)|(abcurl.net)|(ad.vu)|(adf.ly)|(adjix.com)|(afx.cc)|(all.fuseurl.com)|(alturl.com)|(amzn.to)|(ar.gy)|(arst.ch)|(atu.ca)|(azc.cc)|(b23.ru)|(b2l.me)|(bacn.me)|(bcool.bz)|(binged.it)|(bit.ly)|(bizj.us)|(bloat.me)|(bravo.ly)|(bsa.ly)|(budurl.com)|(canurl.com)|(chilp.it)|(chzb.gr)|(cl.lk)|(cl.ly)|(clck.ru)|(cli.gs)|(cliccami.info)|(clickthru.ca)|(clop.in)|(conta.cc)|(cort.as)|(cot.ag)|(crks.me)|(ctvr.us)|(cutt.us)|(dai.ly)|(decenturl.com)|(dfl8.me)|(digbig.com)|(digg.com)|(disq.us)|(dld.bz)|(dlvr.it)|(do.my)|(doiop.com)|(dopen.us)|(easyuri.com)|(easyurl.net)|(eepurl.com)|(eweri.com)|(fa.by)|(fav.me)|(fb.me)|(fbshare.me)|(ff.im)|(fff.to)|(fire.to)|(firsturl.de)|(firsturl.net)|(flic.kr)|(flq.us)|(fly2.ws)|(fon.gs)|(freak.to)|(fuseurl.com)|(fuzzy.to)|(fwd4.me)|(fwib.net)|(g.ro.lt)|(gizmo.do)|(gl.am)|(go.9nl.com)|(go.ign.com)|(go.usa.gov)|(goo.gl)|(goshrink.com)|(gurl.es)|(hex.io)|(hiderefer.com)|(hmm.ph)|(href.in)|(hsblinks.com)|(htxt.it)|(huff.to)|(hulu.com)|(hurl.me)|(hurl.ws)|(icanhaz.com)|(idek.net)|(ilix.in)|(is.gd)|(its.my)|(ix.lt)|(j.mp)|(jijr.com)|(kl.am)|(klck.me)|(korta.nu)|(krunchd.com)|(l9k.net)|(lat.ms)|(liip.to)|(liltext.com)|(linkbee.com)|(linkbun.ch)|(liurl.cn)|(ln-s.net)|(ln-s.ru)|(lnk.gd)|(lnk.ms)|(lnkd.in)|(lnkurl.com)|(lru.jp)|(lt.tl)|(lurl.no)|(macte.ch)|(mash.to)|(merky.de)|(migre.me)|(miniurl.com)|(minurl.fr)|(mke.me)|(moby.to)|(moourl.com)|(mrte.ch)|(myloc.me)|(myurl.in)|(n.pr)|(nbc.co)|(nblo.gs)|(nn.nf)|(not.my)|(notlong.com)|(nsfw.in)|(nutshellurl.com)|(nxy.in)|(nyti.ms)|(o-x.fr)|(oc1.us)|(om.ly)|(omf.gd)|(omoikane.net)|(on.cnn.com)|(on.mktw.net)|(onforb.es)|(orz.se)|(ow.ly)|(ping.fm)|(pli.gs)|(pnt.me)|(politi.co)|(post.ly)|(pp.gg)|(profile.to)|(ptiturl.com)|(pub.vitrue.com)|(qlnk.net)|(qte.me)|(qu.tc)|(qy.fi)|(r.im)|(rb6.me)|(read.bi)|(readthis.ca)|(reallytinyurl.com)|(redir.ec)|(redirects.ca)|(redirx.com)|(retwt.me)|(ri.ms)|(rickroll.it)|(riz.gd)|(rt.nu)|(ru.ly)|(rubyurl.com)|(rurl.org)|(rww.tw)|(s4c.in)|(s7y.us)|(safe.mn)|(sameurl.com)|(sdut.us)|(shar.es)|(shink.de)|(shorl.com)|(short.ie)|(short.to)|(shortlinks.co.uk)|(shorturl.com)|(shout.to)|(show.my)|(shrinkify.com)|(shrinkr.com)|(shrt.fr)|(shrt.st)|(shrten.com)|(shrunkin.com)|(simurl.com)|(slate.me)|(smallr.com)|(smsh.me)|(smurl.name)|(sn.im)|(snipr.com)|(snipurl.com)|(snurl.com)|(sp2.ro)|(spedr.com)|(srnk.net)|(srs.li)|(starturl.com)|(su.pr)|(surl.co.uk)|(surl.hu)|(t.cn)|(t.co)|(t.lh.com)|(ta.gd)|(tbd.ly)|(tcrn.ch)|(tgr.me)|(tgr.ph)|(tighturl.com)|(tiniuri.com)|(tiny.cc)|(tiny.ly)|(tiny.pl)|(tinylink.in)|(tinyuri.ca)|(tinyurl.com)|(tl.gd)|(tmi.me)|(tnij.org)|(tnw.to)|(tny.com)|(to.ly)|(togoto.us)|(totc.us)|(toysr.us)|(tpm.ly)|(tr.im)|(tra.kz)|(trunc.it)|(twhub.com)|(twirl.at)|(twitclicks.com)|(twitterurl.net)|(twitterurl.org)|(twiturl.de)|(twurl.cc)|(twurl.nl)|(u.mavrev.com)|(u.nu)|(u76.org)|(ub0.cc)|(ulu.lu)|(updating.me)|(ur1.ca)|(url.az)|(url.co.uk)|(url.ie)|(url360.me)|(url4.eu)|(urlborg.com)|(urlbrief.com)|(urlcover.com)|(urlcut.com)|(urlenco.de)|(urli.nl)|(urls.im)|(urlshorteningservicefortwitter.com)|(urlx.ie)|(urlzen.com)|(usat.ly)|(use.my)|(vb.ly)|(vgn.am)|(vl.am)|(vm.lc)|(w55.de)|(wapo.st)|(wapurl.co.uk)|(wipi.es)|(wp.me)|(x.vu)|(xr.com)|(xrl.in)|(xrl.us)|(xurl.es)|(xurl.jp)|(y.ahoo.it)|(yatuc.com)|(ye.pe)|(yep.it)|(yfrog.com)|(yhoo.it)|(yiyd.com)|(youtu.be)|(yuarel.com)|(z0p.de)|(zi.ma)|(zi.mu)|(zipmyurl.com)|(zud.me)|(zurl.ws)|(zz.gd)|(zzang.kr)/([a-zA-Z0-9]))"
Etape n°6 – Détecter la langue
Nous allons maintenant transmettre un contenu « propre » et détecter la langue d’un message. Pour chaque fichier, ligne par ligne, nous allons transmettre les messages vers un composant tJava.
Insérez d’abord un composant tFlowToIterate et liez-le au composant tReplace avec un lien « main ». Ce composant nous permet de séquencer la lecture d’un fichier. Ligne par ligne, nous allons transmettre à notre script deux variables : un ID et un texte.
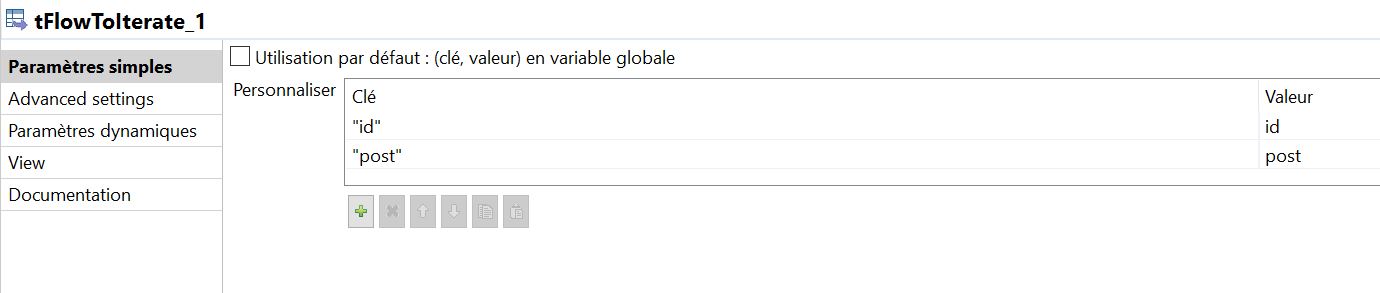
Liez le composant tFlowToIterate à un composant tJava à l’aide d’un lien ‘iterate’ (pour chaque ligne du fichier .csv, on transmet l’id et le texte).

On exécute le code Java, explicité ci-dessous.
// on stocke le message dans une variable 'text'
String text = ((String)globalMap.get("post"));
try{
// on crée une instance 'detector'
Detector detector = DetectorFactory.create();
// on charge le message dans 'detector'
detector.append(text);
// on analyse le message, on stocke le résultat dans un tableau 'langlist' contenant la liste des langues et la probabilité associée
ArrayList<Language> langlist = detector.getProbabilities();
// on ne conserve que la première valeur de ce tableau, c'est à dire la langue avec la plus forte probabilité
String result = langlist.get(0).toString();
// On découpe le résultat dans deux variables : 'lang' conserve le code de la langue (fr, en...) et 'proba', le pourcentage de probabilité
String[] parts = result.split(":");
String lang = parts[0];
Float proba = Float.valueOf(parts[1]);
// On effectue un test. Si la proba < 10% alors on marque la langue comme inconnue
if (proba < 0.1) {lang = "NA";}
// on affiche le résultat dans la console
System.out.println("Message - " +text+ " - langue détectée : " + lang);
// on transmet les données au composant suivant pour les enregistrer dans un fichier. On aura 4 colonnes.
row2.id=((String)globalMap.get("id"));
row2.post=text;
row2.lang = lang;
row2.proba = proba.toString();
}
catch (LangDetectException e) {
// Certains messages ne contiennent peut-être pas assez de caractères pour identifier une langue. On gère l'erreur. //on affiche le message d'erreur dans la console
System.out.println(e.getMessage());
// On transmet le résultat au composant suivant avec l'erreur détectée et une probabilité à zéro
row2.id=((String)globalMap.get("id"));
row2.post=((String)globalMap.get("post"));
row2.lang = e.toString().replace("com.cybozu.labs.langdetect.LangDetectException:","");
row2.proba = "0";
}
Etape n°7 – Enregistrement des résultats
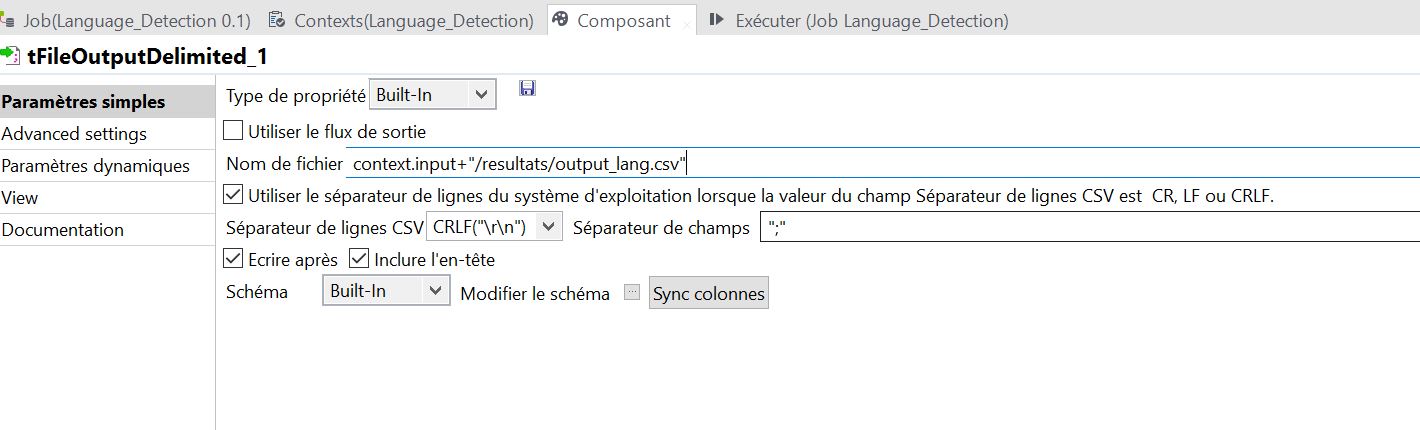
Insérez un composant tFileOutputDelimited. Ce composant enregistre un fichier délimité en sortie de traitement. On commence par configurer le schéma de sortie du fichier, c’est à dire ses 4 colonnes de résultat.

Puis on défini le format du fichier .csv. C’est-à-dire :
- son chemin : on enregistrera le fichier ‘output_lang.csv’ dans un dossier « résultats »
- son encodage : UTF-8 (cf paramètres avancés)
- le délimiteur, l’entourage du texte, etc.
- on coche la case « Ecrire après » pour inscrire les résultats à chaque itération
Il ne reste plus qu’à exécuter le job et admirer le résultat !

6 réponses sur « Tutoriel text mining avec Talend : détecter la langue d’un message »
Bonjour,
Merci pour ce tutoriel.
je suis un doctorant et je travail sur la détection des dialectes arabes. je trouve votre tutoriel est très intéressant qui peut me servir dans mon travail de recherche.
j’ai suivi votre tutoriel pas à pas mais au moment de l’exécution du job, j’ai eu un message d’erreur sur l’objet « tjava_2 ». voici le message:
org.talend.designer.runprocess.ProcessorException: Erreurs de compilation du Job
Au moins le Job « detect_lang » a des erreurs de compilation, réparez et réexportez.
Ligne en erreur: 723
Message détaillé: The method loadProfil(String) is undefined for the type DetectorFactory
Est ce que c’est possible de m’aider pour régler ce problème ?
j’utilise talend for big data 6.5 et java 8 (jvm)
Cordialement,
Bonjour,
Ravi que ce tutoriel vous aide. Je suppose que votre erreur provient de l’étape 3 ==> vous avez faire une erreur de frappe, il s’agit de la méthode loadProfile et non pas loadProfil
cdlt
Bonjour,
Merci beaucoup pour votre aide.
j’ai une autre question par rapport à ce thème, est ce que vous disposez des ressources pour faire l’analyse morphologique et detection des sentiments avec talend
Merci d’avance
J’ai déjà implémenté les librairies de Stanford pour ce genre de traitements ==> nlp.stanford.edu
Je n’ai pas encore rédigé de tutoriel sur ce sujet, mais j’essayerais de le faire si je trouve le temps. Les modèles de Stanford ne sont pas disponibles dans toutes les langues, mais il est possible d’entrainer son propre modèle, et de l’appliquer à son corpus. Je suis preneur de vos feedbacks si vous réaliser l’implémentation.
Bonsoir,
je vais essayé de se familiariser avec votre librairie et de l’intégrer sur talend.
Est ce qu’il y a des exemples et la documentation sur l’utilisation de cette librairie ?
Merci infiniment.
Bonjour Abdellah,
Je viens de publier un tutoriel sur l’usage de Stanford CoreNLP qui pourrait vous aider : http://www.erwanlenagard.com/general/tutoriel-implementer-stanford-corenlp-avec-talend-1354